
Your Team Ships 2x More Pull Requests Since Adopting AI. Your Bug Count Also Doubled.
Huzefa Motiwala February 28, 2026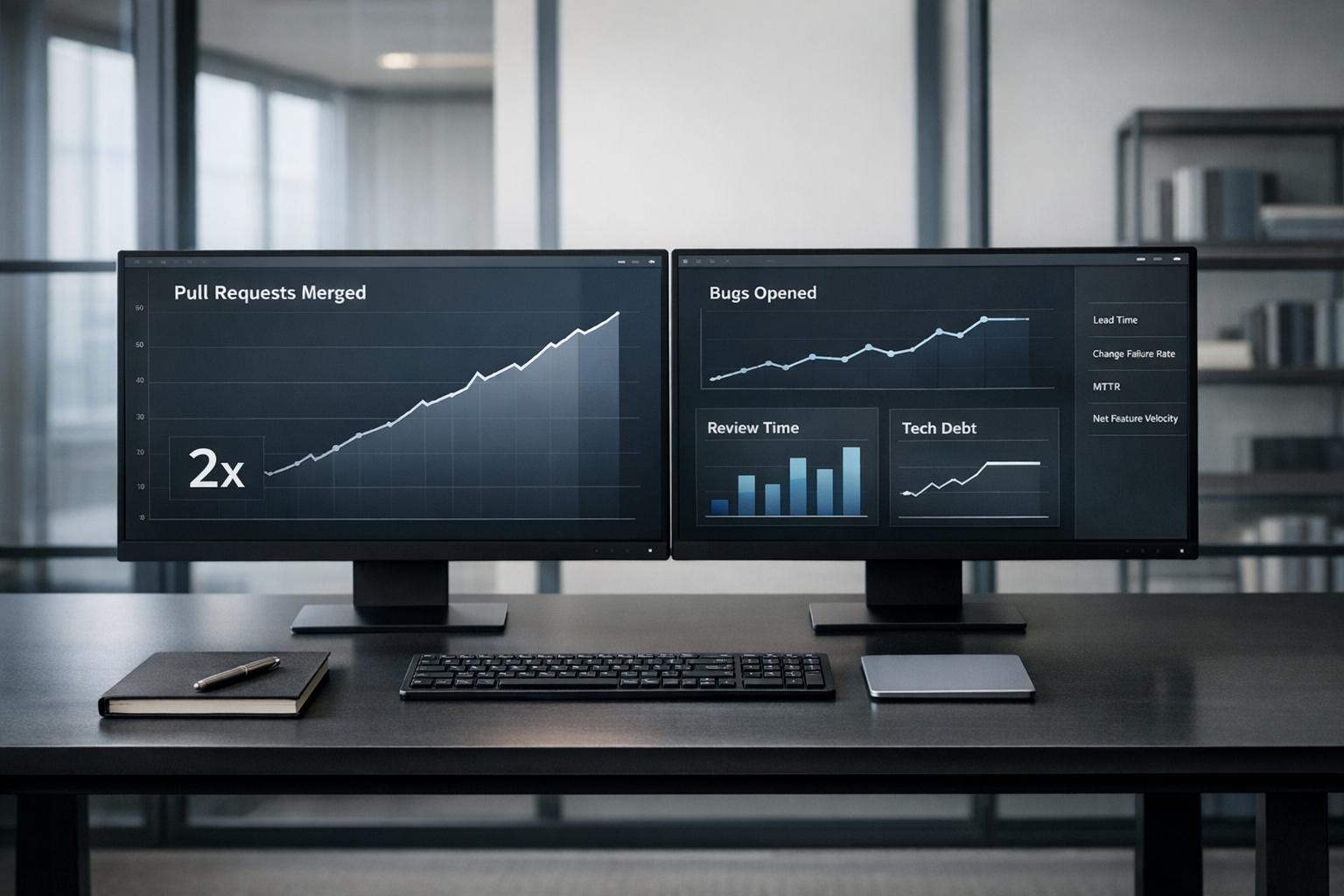
Adopting AI coding tools has led development teams to double their pull requests. But here’s the catch: bug counts have also doubled. While AI tools speed up code generation and increase output, they introduce 1.7x more bugs, 1.75x more logic errors, and 1.57x more security vulnerabilities compared to human-written code.
The result? Teams are spending more time reviewing and debugging AI-generated code, with review times increasing by 91%. Developers feel faster but are actually 19% slower when accounting for rework and fixes. Trust in AI tools has dropped, with only 29% of developers confident in their quality.
Key takeaways:
- AI-generated code issues: 10.83 bugs per pull request vs. 6.45 for human-written code.
- Code churn: Revisions within two weeks have nearly doubled.
- Refactoring decline: Dropped 60%, while copy-pasting surged 48%.
- Technical debt: Poor architecture and duplicated code are creating long-term risks.
To measure real progress, focus on metrics like Net Feature Velocity and DORA metrics instead of pull request counts. Prioritize refactoring, enforce strict review processes, and track AI-specific metrics like the AI Rework Ratio to ensure quality doesn’t take a backseat to quantity.

AI-Generated vs Human-Written Code: Quality Metrics Comparison 2020-2024
What the Data Shows: More Output, Less Quality
The Hidden Cost of 2x More Pull Requests
The data paints a concerning picture: while output has increased, quality has taken a hit. According to GitClear‘s 2025 research, the percentage of copy-pasted code surged from 8.3% in 2020 to 12.3% in 2024 – a staggering 48% jump [7]. Meanwhile, refactored code, which is essential for keeping systems maintainable, plummeted from 24.1% to just 9.5%, marking a 60% decline [7].
2024 was a turning point – it was the first year where copy-pasted code outpaced refactored code [1][10]. Instead of reusing existing logic or refining architecture, teams are duplicating code, a trend encouraged by AI tools that make generating new code blocks quicker than searching for and improving existing ones. This approach often violates the "Don’t Repeat Yourself" (DRY) principle and fosters what some call an "itinerant contributor" style [9][1].
The fallout? AI-heavy repositories now show a 34% higher Cumulative Refactor Deficit compared to traditional ones [8]. Developers are also spending less time improving older code: the percentage of revised code older than a month dropped from 30% in 2020 to 20% in 2024 [7]. Instead, they’re caught up revisiting and fixing recent AI-generated code, leaving legacy systems neglected.
Why AI-Generated Code Creates More Bugs
AI code may look polished, but it often lacks context. AI tools primarily focus on open files, not the broader system, which leads to code that compiles but doesn’t always align with team conventions or system requirements [3]. This can result in subtle logic errors, reliance on outdated methods, or violations of team-specific patterns – issues that often don’t surface until production.
As John Edstrom, Director of Engineering at Augment Code, put it:
"The AI honeymoon is over. What’s left is a hangover." [3]
Another engineering leader summed up the problem bluntly:
"We didn’t get faster. We just moved the traffic jam." [3]
The bottleneck has shifted from writing code to reviewing and debugging it. For AI-heavy teams, code review times have increased by 91% [5], and code churn – revisions made within two weeks – has nearly doubled, climbing from 3.1% to 5.7% [7]. Developers are spending more time fixing AI’s near-misses than reaping the benefits of its speed, leading to rising frustration and skepticism about its value.
The Trust Gap: Why Developers Doubt AI Code Quality
The erosion in code quality has led to a growing lack of trust in AI tools. Despite their widespread use, only 29% of developers trust the quality of AI-generated code [2]. The numbers back up their concerns: 57.1% of duplicated code blocks are linked to bugs, and AI-generated code averages 10.83 issues per pull request compared to 6.45 for human-written code [2].
This trust gap is exacerbated by what’s often called the "LGTM reflex." With the sheer volume of pull requests, reviewers experience fatigue and approve AI-generated code based on surface-level summaries rather than detailed analysis [8]. Participation in code reviews has dropped by 30%, as developers increasingly rely on AI outputs without thorough checks [8].
GitClear’s 2025 report captures the essence of the problem:
"Unchecked acceleration isn’t progress – it is entropy in disguise." [8]
| Metric | 2020 (Pre-AI) | 2024 (AI Era) | Change |
|---|---|---|---|
| Copy/Pasted Code | 8.3% | 12.3% | +48% |
| Refactored Code | 24.1% | 9.5% | –60% |
| Code Churn (2-week) | 3.1% | 5.7% | +84% |
| Newly Added Code | 39% | 46% | +18% |
Source: GitClear 2025 Research [7]
While short-term bug rates may initially appear to decrease by 19%, they climb by 12% over six months as the effects of poor architecture become evident [8]. Additionally, every 25% increase in AI adoption correlates with a 7.2% decline in software delivery stability [5][7].
sbb-itb-51b9a02
Net Feature Velocity: A Better Way to Measure Progress
Defining Net Feature Velocity
Net Feature Velocity tracks how quickly your team delivers customer-facing features to production – not just how much code they write. It adjusts for setbacks like bug fixes and rework, effectively accounting for time lost to cleaning up technical debt [5][13]. The key question isn’t how many pull requests (PRs) your developers opened, but rather: how many features actually made it to production for customers to use?
For instance, a team might merge a flurry of PRs but spend a big chunk of their time fixing bugs. That’s not progress – it’s stagnation. Net Feature Velocity highlights this issue. Consider this: if 7.9% of newly added code is rewritten within two weeks [13], that churn signals wasted effort. This metric shifts the focus to sustained progress, directly tied to delivering value to customers.
Why Pull Request Count Misleads Teams
Counting PRs might seem like a useful metric, but it only reflects how busy your team looks, not the real value they’re creating [11][12]. The rise of AI tools makes this even trickier. AI can churn out lengthy PRs in seconds, but this often slows teams down due to longer review times.
When teams optimize for PR volume, they risk prioritizing shallow work. Developers may ship code they don’t fully understand – sometimes called superficial coding [5]. This creates headaches during debugging since the original context is lost. Review times have surged by 91% [5], leaving senior engineers stuck acting as "human spell-checkers for AI", as one engineering director put it [13].
AI might make writing code faster, but reviewing it remains a time-intensive, manual process. Instead of speeding things up, teams find themselves stuck in a different kind of bottleneck.
Connecting Engineering Metrics to Business Results
Metrics like Net Feature Velocity are crucial for bridging the gap between engineering work and business outcomes. Unlike PR counts, which often obscure the bigger picture, this metric forces teams to ask: Are we delivering features our customers actually use, or are we just cranking out code?
Traditional metrics rarely provide clarity on key goals like revenue growth, system reliability, or faster time-to-market. Net Feature Velocity, on the other hand, focuses on how long it takes to ship a solid feature – one that doesn’t get reverted or rewritten soon after release [12][11]. If PR counts double but feature delivery remains stagnant, it’s a clear sign your team is piling up technical debt.
"When a measure becomes a target, it ceases to be a good measure." – Goodhart’s Law [12]
How to Avoid the AI Productivity Trap
Make Time for Refactoring and Code Maintenance
AI tools make generating new code a breeze, but they don’t handle the mess left behind. Since AI became widely adopted, refactoring activity has dropped by 39.9% [5]. Teams that focus solely on churning out new features risk letting their codebase fall apart. To avoid this, schedule regular refactoring sessions and make maintenance a priority. Keep an eye on your team’s balance between maintenance and new development. If the scales tip too far toward creating new code, you’re likely building up technical debt faster than you can manage [14][1]. As John Edstrom, Director of Engineering at Augment Code, bluntly put it:
"The leaderboard isn’t ‘PRs opened per week.’ It’s ‘months since the last mass refactor’" [3].
Another way to gauge your team’s efficiency is to track code churn. High churn levels often signal wasted effort, where the team is redoing work instead of making real progress [5][15]. Once your maintenance process is in place, shift your focus to tracking metrics that reflect meaningful progress.
Track Metrics That Reflect Real Progress
To understand if your team is truly moving forward, focus on metrics that matter. The four DORA metrics – deployment frequency, lead time for changes, change failure rate, and time to restore service – are excellent indicators of whether your team is delivering real value or just staying busy [14][15].
For AI-generated code, it’s important to go a step further. Tag commit-level contributions to evaluate how AI-generated code performs [18][5]. One key metric to track is the AI Rework Ratio, which measures the percentage of AI-generated code that needs fixes within 30 days of being merged. If this ratio keeps climbing, it’s a sign that AI might be causing more headaches than it solves. A study from 2025 revealed that AI-generated code has 1.7x more defects than human-written code when review practices are weak [18].
Another critical metric is investigation time – the time developers spend trying to understand existing code. If investigation time increases, it could mean that AI tools are creating knowledge silos, where no one fully understands how the system works [12].
Use AI Tools With Clear Boundaries
Clear boundaries are essential to maintaining quality and stability when using AI tools. Treat AI-generated code as untrusted input. Implement an engineer-in-the-loop policy, requiring human review and alignment with system requirements before merging any AI-generated code [5][3]. This is especially important given that only 3% of developers "highly trust" AI-generated code, and overall trust in these tools dropped from 70% to 60% in 2025 [15].
Avoid rubber-stamping AI-generated pull requests. Make it a rule: if you didn’t thoroughly review the code, you can’t approve the PR [3]. While AI can help summarize and triage issues, the final decision should always rest with a human.
To further safeguard quality, build context infrastructure for your AI tools. For example, create an ARCHITECTURE.md file to document your team’s approved dependencies, error-handling patterns, naming conventions, and banned practices [16]. Additionally, integrate custom linting rules into your CI pipeline to catch AI-specific errors – like redundant mocks or outdated methods – that human reviewers might overlook [16][17]. At Apollo.io, introducing these "Quality Gates" allowed a 250-engineer team to block AI-related bugs and noise before they ever reached production [17].
"AI is an amplifier. It magnifies whatever’s already there. Strong engineering culture… AI makes all of that better. Weak foundations… AI pours gasoline on the fire." – 2025 DORA Report [15]
Conclusion: Measuring What Actually Matters
What Founders and CTOs Need to Remember
Pull request (PR) volume may indicate activity, but it doesn’t always reflect true progress. For example, doubling your PR count while also doubling your bug count doesn’t mean you’re moving faster – it often just creates more work. AI tools can amplify your team’s existing engineering culture, for better or worse. If your team lacks strong review practices or clear architectural guidelines, AI can actually make those issues worse.
Here’s what the data tells us: AI-generated code introduces 1.7x more defects per pull request [4][6]. Reviews take 91% longer, and pull requests grow by 154% in size [5][6]. While this might feel like speed, it often overwhelms senior engineers, creating a perfect storm for technical debt to pile up quickly.
"Unchecked acceleration isn’t progress. It’s entropy disguised as productivity." – GitClear Report 2025 [8]
To avoid this trap, focus on metrics that actually matter. One key metric is Net Feature Velocity – the measurable progress toward business goals after accounting for rework, bugs, and maintenance. In addition, prioritize DORA metrics like deployment frequency, change failure rate, and time to restore service [5]. Shifting your focus from raw output to meaningful progress can make all the difference.
How AlterSquare Helps Teams Focus on Real Velocity
Navigating these challenges requires a strategic approach, and that’s where AlterSquare steps in. Their team, led by the Principal Council – Taher (Architecture), Huzefa (Frontend/UX), Aliasgar (Backend), and Rohan (Infrastructure) – conducts a comprehensive audit using their proprietary AI-Agent Assessment. This generates a System Health Report that identifies architectural coupling, security risks, performance problems, and areas of technical debt. The findings are then organized into a Traffic Light Roadmap, categorizing issues as Critical, Managed, or Scale-Ready [19].
AlterSquare’s Variable-Velocity Engine (V2E) framework adapts to your company’s stage of growth. For early-stage startups, it employs Disposable Architecture to drive quick revenue. For growth-stage companies, it uses Managed Refactoring to scale systems without disruption. For mature startups preparing for an exit, it emphasizes governance and operational efficiency. This approach doesn’t just reduce technical debt – it manages it systematically, ensuring teams can deliver faster while maintaining system health. By aligning engineering metrics with business goals, AlterSquare ensures that your growth is both sustainable and scalable.
3 data-backed ideas to deter AI code quality problems | Bill Harding | LeadDev New York 2025
FAQs
How do we calculate net feature velocity?
Net feature velocity gauges a development team’s effectiveness by balancing the quantity of work delivered with its quality. It measures how quickly valuable features are shipped while considering factors like pull requests, bug reports, rework, and technical debt. Relying solely on pull request volume can be deceptive – AI tools may inflate activity without necessarily improving code quality. To get a clearer picture of progress and maintainability, it’s crucial to pair throughput metrics with quality indicators.
What AI-specific metrics should we track?
To gauge how AI coding tools are performing, start with net feature velocity – a metric that combines pull request (PR) volume, quality, and the amount of rework needed. Beyond that, keep an eye on other indicators like code duplication rates, how often refactoring happens, and bug rates to get a sense of overall code quality. It’s also important to measure trust in AI-generated suggestions. While adoption rates are high, confidence in these tools still has room to grow. Tracking these metrics helps ensure AI tools boost productivity without compromising the quality of your software.
How do we cut AI bugs without slowing down?
To keep AI bugs in check without sacrificing speed, put emphasis on thorough code reviews and testing methods specifically designed for AI-generated code. Boost automated testing and static analysis tools to identify problems early in the process. Focus on achieving "net feature velocity", which means prioritizing quality and stability over sheer output. Encourage ongoing reviews and regular refactoring to keep technical debt under control. This way, you can maintain AI productivity while safeguarding code quality.






Leave a Reply