
Ship Fast Without the Fallout: The Framework We Use to Manage Tech Debt at Every Stage
Huzefa Motiwala April 11, 2026
Managing technical debt is critical for shipping fast without compromising your product’s future. Startups face a tough balance: move quickly to find product-market fit or risk falling behind. But ignoring technical debt can lead to costly overhauls, reduced productivity, and customer churn.
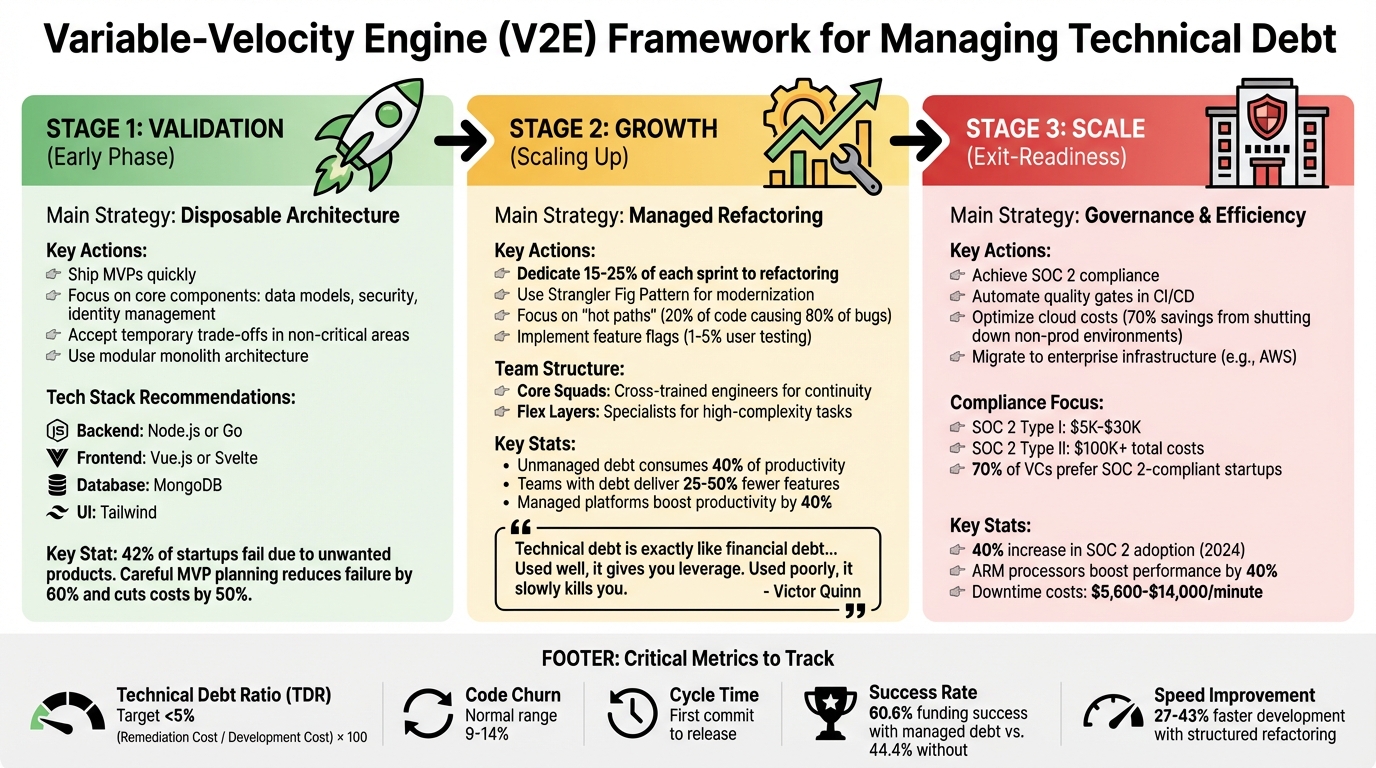
Here’s how AlterSquare’s Variable-Velocity Engine (V2E) framework tackles this problem across three key stages:
- Validation Stage (Early Phase): Use "Disposable Architecture" to ship MVPs quickly. Focus on core components like data models and security while accepting temporary trade-offs in non-critical areas.
- Growth Stage (Scaling Up): Dedicate 15–25% of each sprint to refactoring. Use techniques like the Strangler Fig Pattern to modernize systems without halting feature development.
- Scale Stage (Exit-Readiness): Prioritize governance, SOC 2 compliance, and cost optimization. Automate quality checks and focus on performance improvements.
Key metrics to track: Technical Debt Ratio (TDR), Code Churn, and Cycle Time. Tools like AI-powered assessments and Traffic Light Roadmaps help prioritize fixes based on risk and cost.
The takeaway? Technical debt, when managed wisely, can be a tool for growth instead of a liability.
V2E Framework: Managing Technical Debt Across Three Startup Stages
Validation Stage: Disposable Architecture for Fast MVPs
Why Disposable Architecture Works for MVPs
When you’re in the race to validate product-market fit, the focus should be on speed and survival – not perfection. Disposable Architecture operates on the assumption that some parts of your product will need to be rebuilt as it grows. This approach helps you avoid over-engineering, allowing you to concentrate on proving demand.
It’s okay to take shortcuts on less critical elements, like UI frameworks or admin tools. However, never compromise on the foundational components – your "load-bearing beams." These include core data models, security systems, identity management, and financial ledgers. Victor Quinn, Co-founder and CTO of Texture, explains it well:
"Technical debt is exactly like financial debt. It’s not moral. It’s not a sin. It’s a tool. Used well, it gives you leverage. Used poorly, it slowly kills you" [1].
The stakes are high: 42% of startups fail because they create products no one wants [3]. Careful planning during the MVP stage can lower failure rates by 60% and cut development costs by up to 50% [3]. To manage the trade-offs of this approach, document your shortcuts using tools like TODOs, an Architecture.md file, or a debt register. This ensures that temporary compromises don’t turn into long-term liabilities.
This mindset sets the stage for choosing the right tech stack to support rapid development.
Golden Path Tech Stack for Speed and Flexibility
At this stage, your tech stack should prioritize simplicity and speed over theoretical scalability. AlterSquare’s Golden Path approach suggests starting with a modular monolith – a single application divided into independent modules with clear boundaries. This setup simplifies deployment while keeping the door open for future transitions to microservices.
For quick validation, consider using Node.js or Go for backend development, paired with Vue.js or Svelte for the frontend. MongoDB works well for rapidly evolving data models. To save time, leverage UI libraries like Tailwind and managed PaaS platforms. Teams using managed platforms often report a 40% boost in productivity and faster MVP launches [3].
From day one, include basic observability tools – logging, metrics, and tracing – so you can identify and address issues quickly. Use feature flags to test changes with a small percentage of users (1–5%) before rolling them out broadly [3]. Focus on delivering one key user story, such as onboarding, and leave secondary features for later [2].
With this streamlined tech stack, you’re well-positioned to shift your focus to scaling your MVP into a revenue-generating product.
Moving from MVP to Revenue: What to Prepare For
As your MVP starts to gain traction, transitioning to a scalable architecture becomes essential. A modular monolith design can make this shift smoother by organizing your code into independent modules with clear interfaces. This allows you to upgrade or replace parts of the system without disrupting the entire application.
Texture provides a great example of this approach. They initially used RedwoodJS and Tailwind for their dashboard to validate market fit. Once they had proof, they rebuilt using a custom design system and transitioned from Render to AWS to meet enterprise SOC2 compliance standards. This move reduced their audit costs by a factor of seven [1]. The takeaway? Know when to take shortcuts and when to address them.
As you approach revenue milestones, align with the V2E framework to prepare for Managed Refactoring. Protect your foundational components – such as money-movement systems, security layers, and core data models – since fixing these later can be costly. While speed remains important, recognizing when to slow down and reinforce your architecture is equally critical.
sbb-itb-51b9a02
Growth Stage: Managed Refactoring for Scaling Without Breaking
When to Trigger Refactoring and Stabilization
Refactoring becomes a must when your development speed starts to drag. If tasks that used to take a few days now stretch into weeks, it’s a clear sign that tech debt is piling up – and the "interest" on that debt is getting too costly to ignore [4]. Another red flag? When developers are spending over 20% of their time fixing bugs instead of building features, or when only 30–40% of their capacity is going toward actual product development, it’s time to act [1][4].
Sometimes, business milestones force your hand. For instance, hitting revenue targets might attract enterprise customers who require SOC 2 compliance. Or, your architecture may start crumbling under traffic spikes it wasn’t built to handle [1]. These moments make it impossible to keep pushing stabilization work to the back burner. High regression rates – where fixing one bug keeps breaking other features – are another clear indicator that your system has become too fragile to scale safely [4].
Unmanaged technical debt can sap as much as 40% of your team’s productivity [1][4], and teams overwhelmed by debt deliver 25–50% fewer features [4]. To counteract this, dedicate 15–25% of every sprint specifically to tackling tech debt during this phase of growth [1][4]. Focus on the "hot paths", which are the 20% of your codebase responsible for 80% of bugs and performance bottlenecks [1]. When presenting this to stakeholders, frame the problem in terms of dollars and time, like: “This module delays every feature by two weeks, costing $180,000 per quarter” [1].
Once you’ve addressed the immediate issues, it’s time to look at modernizing your systems without pausing feature development.
Modernizing Systems Without Stopping Feature Development
You don’t have to choose between building new features and fixing outdated code. With approaches like the Strangler Fig Pattern, you can modernize your systems incrementally. This method allows you to build new components alongside legacy ones, gradually shifting traffic to the updated parts without disrupting your roadmap [1]. Tools like reverse proxies or API gateways can help route requests, letting you modernize piece by piece while keeping the rest of your application running smoothly.
Take Airbnb’s example. In July 2024, they transitioned from React 16 to React 18 using a "React Upgrade System." This system used module aliasing and environment targeting to run A/B tests in production while maintaining a "permitted failures" list in their test suite. The result? A complete rollout with zero rollbacks and no interruptions to ongoing feature work [5]. Incremental migrations like this show how you can update critical systems without stalling progress.
Feature flags are another powerful tool. By decoupling deployment from release, you can roll out changes to a small percentage of users – say 1–5% – and closely monitor performance. Once you’re confident in the stability, you can scale up to 100% [5]. Additionally, creating a reusable component library can help standardize UI elements across your product, speeding up modernization efforts and ensuring consistency. For large-scale refactors, start with high-value, frequently updated pages by using an impact-versus-effort matrix to prioritize [5].
With systems modernized, the next step is optimizing your team structure to handle growth and complexity.
Using Core Squads and Flex Layers for Scalability
As your product grows, your team structure needs to evolve to manage both stability and specialized challenges. Core Squads should consist of cross-trained engineers who own the product’s context and continuity. These teams stay stable, avoiding frequent rotations, so they can make decisions quickly without constant onboarding.
Flex Layers, on the other hand, are made up of specialists brought in for high-complexity tasks like AI integration, DevOps automation, security upgrades, or performance tuning. These specialists work alongside Core Squads to handle specific challenges and step away once their expertise is no longer needed. This approach ensures that your core team isn’t stretched too thin while still benefiting from expert execution.
Companies that adopt modern frameworks and managed infrastructure often see productivity improvements of 20–30%, while also cutting operating costs by up to 30% [5]. Victor Quinn, Co-founder and CTO of Texture, sums it up perfectly:
"The ones that win aren’t the ones with zero technical debt. They’re the ones that take it on intentionally, in the right places, and then pay it down ruthlessly before the interest gets crushing" [1].
Scale Stage: Governance and Efficiency for Exit-Readiness
Optimizing Architecture for Scalability and Governance
As you move beyond the early stages of MVP development and initial refactoring, scaling demands a shift in priorities. It’s no longer just about speed – precision and governance take center stage. To handle enterprise-level demands, your infrastructure needs to evolve.
By the time you hit $10M ARR, it’s time to transition from developer-friendly platforms to systems built for enterprise compliance and heavy workloads [1]. This is when startups typically migrate from solutions like Render to more robust platforms such as AWS. A great example is Texture’s move in March 2026, which reduced audit costs and met enterprise compliance needs, sending a clear message to clients and potential acquirers about their readiness [1].
To stabilize your foundation, integrate automated quality gates into your CI/CD pipelines. These gates ensure pull requests meet minimum coverage and complexity thresholds, preventing the accumulation of technical debt. Without these safeguards, unchecked debt can eat away up to 40% of your company’s technology value [1]. Every measure you take now helps secure your platform for the future.
Additionally, establish a second layer of leadership, such as VPs, to own key KPIs. This relieves founders from being bottlenecks and helps standardize operations [6]. At this stage, scaling 3×–5× requires systems that reduce fragility, including streamlined revenue operations and customer onboarding processes [6].
This phase is all about aligning your platform and operations with enterprise expectations, ensuring you’re prepared for rapid growth and future opportunities.
SOC 2 Compliance and Security Posture
SOC 2 compliance becomes non-negotiable at this stage. It’s a critical step for attracting enterprise clients and preparing for potential acquisitions. Developed by the AICPA, SOC 2 demonstrates your ability to protect customer data across five key criteria: Security, Availability, Processing Integrity, Confidentiality, and Privacy [9][10].
There are two types of SOC 2 reports to consider. Type I evaluates the design of your controls at a specific point in time, while Type II assesses their effectiveness over 3–12 months [9][12]. Type I audits cost between $5,000 and $30,000, but total compliance costs – including consulting and Type II audits – can exceed $100,000 [9][11].
SOC 2 compliance has become increasingly common, with adoption rising by 40% in 2024 as startups aimed to meet enterprise demands [12]. Investors and partners value this certification – 70% of VCs prefer SOC 2-compliant startups, and over 60% of businesses are more likely to collaborate with companies that meet this standard [12]. For instance, Kolide achieved both SOC 2 Type I and Type II compliance between 2017 and 2019, streamlining their audit process by documenting 11 core policies and using their own security product to provide automated evidence [11].
To get started, formalize your risk management by maintaining a "Risk Register." This document identifies potential threats, assesses their impact, and outlines mitigation strategies [12]. Strengthen your security posture by enforcing identity controls like Single Sign-On (SSO) and Multi-Factor Authentication (MFA), as weak credentials account for 62% of data breaches [12]. Implement Role-Based Access Control (RBAC) to limit access based on job responsibilities, ensuring employees only have permissions necessary for their roles [12].
Once compliance is secured, your focus should shift toward improving performance and managing costs effectively.
Performance Improvements and Cost Optimization
At this stage, the goal is to balance performance and cost efficiency while preparing for potential exits. Cloud expenses can escalate quickly, but there are practical ways to keep them in check without sacrificing quality.
Start by optimizing resource usage. Non-production environments like development, staging, and QA don’t need to run around the clock. Since non-working hours account for 70% of the week [7], shutting down these resources during off-hours can lead to immediate savings. Use resource tags to distinguish between production and non-production environments, and automate scripts to shut down idle systems [7].
Another cost-saving measure is hardware modernization. Upgrading to the latest instance types or adopting ARM-based processors like AWS Graviton2 can boost price-performance by up to 40% with minimal code changes [7]. Additionally, commitment-based savings plans for services like EC2, Fargate, and Lambda can help you manage costs while accommodating evolving needs [7].
To prioritize optimization efforts, apply the 80/20 rule. Focus on the 20% of processes causing 80% of bottlenecks [8]. Companies that actively manage technical debt at this stage have a higher funding success rate of 60.6%, compared to 44.4% for those with slower codebases [1].
The aim isn’t to eliminate all technical debt but to ensure your systems are robust enough to meet the demands of enterprise clients, investors, and acquirers without faltering under pressure.
Taming Your Technical Debt: Mastering the Trade-Off Problem – Andrew Brown
Traffic Light Roadmap: How to Prioritize Tech Debt Decisions
Once you’ve optimized your systems and tackled initial refactoring, the next challenge is deciding how to handle the rest of your technical debt. Not every piece of debt requires immediate attention, and treating it all as urgent can stall progress entirely.
The Traffic Light Roadmap helps cut through the noise by sorting technical debt into two key dimensions: Interest (the ongoing cost of inefficiency or delays) and Risk (the likelihood of system failures or security issues) [14]. This framework simplifies prioritization, turning an overwhelming backlog into a clear, actionable plan that aligns with your business goals. It ensures engineering teams focus their efforts where they’ll make the biggest impact.
Today, over 90% of organizations wrestle with technical debt, with engineers spending about 33% of their time managing it instead of creating new value [14].
The AI-Powered System Health Report
To prioritize effectively, you need visibility. AlterSquare’s AI-Agent Assessment scans your codebase for "hotspots" – areas where complexity, duplication, or error rates hint at potential problems. It tracks metrics like cyclomatic complexity and duplicate code ratios, which can balloon – say, from 3.1% to 14.2% – without proper oversight [1].
The System Health Report organizes findings into three tiers:
- Critical (Red): This is the most urgent category. It includes code prone to frequent crashes, security vulnerabilities, or issues within critical revenue paths like login or checkout [14]. Addressing this "toxic debt" should be the top priority.
- Managed (Yellow): This category covers code that hampers developer productivity but doesn’t cause frequent failures [14]. Known as "friction debt", it can be tackled incrementally during regular development cycles.
- Scale-Ready (Green): This includes unoptimized or "ugly" code in areas that are rarely touched or modified [14]. Since the cost of maintaining this code is minimal, it’s usually best to leave it alone.
There’s also a fourth category:
- Strategic Blocker Debt: This refers to legacy systems that limit growth or prevent scaling into new markets [14]. Unlike routine maintenance, addressing this debt is treated as a capital project with a clear return on investment.
Unplanned IT downtime can cost anywhere from $5,600 to $14,000 per minute [14]. The AI-powered assessment helps identify these high-risk areas before they lead to costly disasters.
Aligning Debt Prioritization With Business Goals
The Traffic Light Roadmap doesn’t just organize debt – it ties prioritization to business outcomes. Technical data alone can’t determine what to fix first. That’s where the Principal Council comes in – a team of technical and business leaders who contextualize the AI findings to ensure remediation efforts support both growth and stability.
For instance, instead of dismissing a module as simply "messy", the Council quantifies its impact: "This module delays every feature by two weeks, costing $180,000 per quarter" [1]. Strategic debt management has been shown to improve funding success rates to 60.6%, compared to 44.4% without it [1].
To keep the roadmap credible, allocate 15% to 25% of each sprint to resolving prioritized technical debt [13][15]. Additionally, include a small "refactoring tax" (around 10%) in every major feature estimate to address related code issues during development [14]. And don’t forget the 90-Day Rule: treat any unresolved tech debt lingering for more than 90 days as critical [16].
The Traffic Light Roadmap is more than a categorization tool – it’s a strategy to align engineering work with business priorities. By focusing efforts where they matter most, you ensure every hour and dollar spent on refactoring delivers measurable results.
Implementing V2E: Metrics, Policies, and Continuous Integration
After prioritizing debt management strategies, the next step is to bring in metrics, policies, and continuous integration to put V2E into action. For V2E to work, you need clear metrics and enforceable policies. By embedding debt tracking and remediation into your workflow, you can avoid unpleasant surprises down the road.
Metrics for Tracking Tech Debt
Start with metrics that reveal the state of your codebase and the effects of tech debt. The Technical Debt Ratio (TDR) is a key metric: calculate it as (Remediation Cost / Development Cost) x 100. Ideally, TDR should stay below 5% [18]. If it exceeds this threshold, it means more time is being spent fixing old issues instead of creating new features.
To assess code quality, monitor Code Churn, which typically ranges from 9% to 14%. Higher churn rates may signal rushed fixes [17]. Keep an eye on Cyclomatic Complexity to spot overly intricate modules, and track Defect Density (bugs per unit of software size), especially in high-traffic areas [17][18].
From a delivery perspective, measure Cycle Time (from first commit to release) and Change Failure Rate to identify where tech debt may be slowing progress [17][19]. If your CI pipeline time increases by more than 10% month-over-month, it’s a red flag that requires immediate attention [22]. Companies that actively manage these metrics often achieve 50% faster service delivery times [18][19].
Policies for Sustainable Tech Debt Management
Metrics are only useful if paired with policies that ensure time and resources are allocated to addressing tech debt. Formalize sprint allocations by dedicating 15% to 25% of every sprint to maintenance and refactoring [1]. This isn’t wasted time – it’s an investment that helps avoid the 40% capacity loss caused by unmanaged debt [1].
Revise your Definition of Done to include automated testing and refactoring. A task isn’t "done" until it’s fully tested and ready for deployment [20]. Add a simple but critical question to every code review: "Does this change increase, decrease, or maintain the current level of technical debt?" [22]. This encourages developers to think carefully about the shortcuts they take.
For AI-generated code, require developers to explain AI-written logic during reviews and use tools like jscpd to detect duplicate code. AI usage can significantly increase duplicate code ratios (from 3.1% to 14.2%) and nearly double cyclomatic complexity (from 4.2 to 8.1) [1]. As Victor Quinn, CTO of Texture, wisely noted:
"Every line of code is a loan against our future. Let’s make sure the robot isn’t borrowing in our name without checking the interest rate" [1].
Once these policies are in place, the next step is integrating them into your CI/CD pipeline for continuous improvement.
Continuous Integration and Incremental Improvements
The most effective way to handle debt is to prevent it from piling up in the first place. Incorporate automated quality gates into your CI/CD pipeline to ensure pull requests meet coverage and complexity standards [1]. Use feature flags for dark deployments (testing with 1%–5% of users) and the Strangler Fig Pattern to gradually replace legacy components with the help of a routing layer like a reverse proxy or API gateway [3].
Keep a close watch on your CI pipeline metrics. If build or test suite durations start to climb, it’s a sign of bottlenecks that need immediate attention [22]. Within CI, apply the Impact-Effort Matrix to prioritize fixes: focus on high-impact, low-effort tasks during the current sprint and schedule high-impact, high-effort work for the next quarter [22]. Concentrate on the 20% of your codebase (the "hot paths") responsible for 80% of bugs and performance issues [21][1].
Conclusion: Ship Fast Without the Fallout
Key Takeaways for Founders and CTOs
V2E offers a roadmap for navigating every stage of your startup journey. During the Validation Stage, the focus is on shipping quickly using Disposable Architecture while protecting critical systems like data models, security, and identity management [1]. As you transition to the Growth Stage, adopt Managed Refactoring by allocating 15% to 25% of each sprint to addressing tech debt, particularly in your "hot paths" – the 20% of code responsible for 80% of your bugs [1][23]. When you reach the Scale Stage, shift priorities to Governance and Efficiency: strengthen your infrastructure, achieve SOC2 compliance, and limit new debt to prepare for exit-readiness [1].
Keep track of every intentional shortcut by maintaining a debt register or an Architecture.md file to avoid unexpected liabilities. Monitor your Technical Debt Ratio (TDR) and aim for an ideal 5% [23]. Use feature flags for controlled releases and apply the Strangler Fig Pattern to gradually replace outdated components [3]. For AI-generated code, treat it cautiously – require developers to review and explain its purpose to avoid potential pitfalls [1].
These practices help transform tech debt from a liability into a tool for growth and speed.
Why Intentional Tech Debt Is a Growth Tool
When managed intentionally, tech debt becomes a strategic advantage. Startups that actively track and manage their debt see a 60.6% funding success rate, compared to 44.4% for those with slower, cleaner codebases [1]. The goal isn’t perfection from the start – it’s about moving fast enough to fix imperfections later. Victor Quinn, CTO of Texture, put it best:
"Technical debt is exactly like financial debt. It’s not moral. It’s not a sin. It’s a tool. Used well, it gives you leverage. Used poorly, it slowly kills you" [1].
Intentional tech debt – whether through Disposable Architecture or Managed Refactoring – helps startups enter the market faster and validate their products. Companies that adopt structured refactoring programs report a 27% to 43% increase in development speed and a 32% to 50% reduction in post-release defects [23]. Success doesn’t come from avoiding debt altogether; it comes from taking it on strategically, targeting the right areas, and aggressively paying it down before it spirals out of control [1].
FAQs
How do I know which tech debt is safe to take on now?
To determine which technical debt is worth taking on, you’ll need to evaluate how it aligns with your business goals and what effect it might have on your product’s stability and growth. Prioritize debt that’s intentional and carefully monitored – this kind of debt can help accelerate development without creating significant risks. Tools like a Traffic Light Roadmap can be helpful for categorizing debt into manageable groups. This approach ensures the debt can be tackled later through planned refactoring, all while keeping your product stable.
What are the fastest signs we need a refactoring sprint?
The most obvious signs that it’s time for a refactoring sprint include performance issues like sluggish load times or difficulty managing traffic surges. Then there are codebase challenges, such as recurring bugs, disorganized code that developers shy away from, or a growing list of unresolved issues. Other red flags? Slower development cycles, escalating maintenance expenses, and a rising rate of failed changes. These symptoms all point to the need to refocus on improving efficiency and stabilizing your system.
How do we set up a Traffic Light Roadmap for our backlog?
To build a Traffic Light Roadmap, sort your backlog items by priority using a simple color-coded system:
- Red: These are critical tasks that demand immediate attention. They can’t be delayed without causing serious issues.
- Yellow: These are important but manageable tasks that should be addressed in the near future.
- Green: These tasks are stable and can be deferred without any immediate consequences.
Make it a habit to review and adjust these categories regularly, aligning them with evolving business priorities and technical needs. This approach helps you stay focused on urgent matters while keeping tech debt under control.
Related Blog Posts
- How Frontend Teams Accumulate Technical Debt Without Realizing It
- Every Startup Has Tech Debt. The Ones That Die Are the Ones That Pretend They Don’t.
- The Hidden Cost of ‘Move Fast and Break Things’ When Your System Already Has 200K Users
- What Every Experienced CTO Wishes They’d Done Differently About Technical Debt






Leave a Reply