
Why VAD End-of-Speech Detection Is the Hardest Problem in Production Voice Agents
Taher Pardawala April 17, 2026
Voice Activity Detection (VAD) is the backbone of turn-taking in voice agents, deciding when to stop listening and start responding. But in production, it struggles with natural speech patterns, background noise, and user pauses. Here’s why it’s so challenging:
- Natural Pauses vs. Turn Completion: Humans pause while thinking or mid-sentence. VAD often misinterprets these as the end of speech, leading to interruptions.
- Noise Confusion: Background sounds like typing or music can trigger false detections, making the system respond unnecessarily.
- Threshold Tradeoffs: Short silence thresholds risk cutting users off, while long ones cause frustrating delays.
- Metrics Mismatch: Standard tests like precision and recall don’t reflect real conversational performance, where timing and flow matter more.
Solutions include fine-tuning parameters (e.g., silence duration) and hybrid systems that combine acoustic and semantic analysis. These approaches improve detection by factoring in both speech patterns and context, ensuring smoother interactions.
Semantic Turn Detection Explained: Making Voice Assistants Feel Human
sbb-itb-51b9a02
Why VAD Fails in Production After Passing Tests
Even if your Voice Activity Detection (VAD) system excels in controlled tests, it might not perform as well in the unpredictable environments of real-world usage. Think about users speaking from their cars, kitchens, or bustling coffee shops – these conditions are far messier than a testing lab.
Clean Training Data vs. Messy Production Audio
Most VAD models are built using clean, high-quality datasets where speech and silence are clearly defined. But production audio is a whole different story. Traditional VAD systems, like WebRTC, rely on Gaussian Mixture Models (GMM) and energy-based thresholds. These methods work fine with clean, headset-recorded audio but often fail in noisy, dynamic environments. Background sounds like typing, music, TV chatter, or traffic can easily confuse these systems [5][8].
For example, at a 5% false positive rate, WebRTC VAD misses about 50% of speech frames in real-world conditions. Neural VADs do better: Silero VAD misses roughly 12.3% of frames, while Cobra VAD misses only 1.1%. However, even advanced models can struggle with "voice-like" noises. A TV playing in the background or music with vocals can trick the system into detecting speech when none exists, leading to false positives and unnecessary processing [8].
Why Standard Metrics Don’t Predict Real Performance
Metrics like precision, recall, and F1 scores treat VAD as a straightforward "speech or silence" classification task. But these numbers don’t always reflect how the system performs in practical, user-facing scenarios. A system might score perfectly on these metrics and still feel awkward or disruptive in real conversations [1].
"A system can have perfect VAD and still have terrible turn-taking UX." – Talkflow AI [1]
Metrics like endpoint delay (the time it takes for the system to respond) and cutoff rate (how often the system interrupts users) are often overlooked. For instance, adjusting the silence threshold by just 100 milliseconds can mean the difference between a system that feels responsive and one that constantly cuts users off mid-sentence [3]. These subtle issues might only surface when real users start reporting problems.
Common Failure Patterns in Production
In real-world settings, VAD failures tend to follow predictable patterns:
- Premature cutoffs: Natural pauses, such as when a user is thinking or preparing to say something important (like a name or number), can be misinterpreted as the end of their turn. This causes the system to interrupt, often mid-sentence [1][2].
- False triggers: Background noises – typing, doors closing, or even a cough – can activate the VAD, making the system respond when no one is actually speaking [5][8].
- Echo-related issues: Without proper Acoustic Echo Cancellation (AEC), the system’s own voice can bleed into the microphone, tricking the VAD into thinking the user is speaking. This can lead to the system interrupting itself [4][7].
Another challenge lies in the "hangover time" setting, which keeps the VAD active for a brief period after detecting speech. A shorter hangover (around 200 milliseconds) makes the system feel snappier but risks cutting off utterances prematurely. A longer hangover (around 1,000 milliseconds) avoids this but adds noticeable delays to the conversation flow [1][5]. Balancing these settings is crucial but tricky, as both extremes have tradeoffs.
What Causes Premature and Delayed End-of-Speech Detection
To understand why Voice Activity Detection (VAD) sometimes fails in real-world scenarios, it’s important to look at how acoustic signals interact with detection models. These challenges go beyond mere configuration issues and delve into how models interpret the complexities of human speech.
Problem 1: Noisy Environments Distort VAD Confidence Scores
VAD models often struggle when they move from clean training environments to noisy, unpredictable real-world settings. For instance, calibration errors can cause confidence scores to deviate by as much as 20 percentage points. This means a model might output an 80% confidence score when the actual probability of speech is closer to 60% [11].
Background noise – like sounds from HVAC systems, traffic, or even television – can confuse the model, leading to distorted confidence outputs. On top of that, "voice-like" noises such as coughing, laughter, or the rustling of paper can trick the system into false positives because they share some acoustic similarities with human speech [9][10][12].
"Off-the-shelf VAD models are trained on clean speech corpora. Deploy them on real-world audio (e.g., noisy environments, accented speech, cross-talk) and the probabilities they output are wrong."
Other challenges include plosives (like "p" or "t"), breaths, and pauses between words, which can cause momentary dips in speech probability. These dips are sometimes misread as the end of a conversational turn. Additionally, microphone setups that pick up an agent’s voice (echo) can lead to false detections, causing the system to interrupt itself [4].
Even beyond noise issues, the way VAD processes audio frames can create problems with natural pauses.
Problem 2: Frame-Level Thresholds Can’t Handle Natural Pauses
Most VAD systems divide audio into short frames, typically lasting 20–32 milliseconds [6][4]. They then use thresholds to detect when speech has ended. However, this approach can fail when speakers pause naturally – such as when gathering their thoughts or preparing to say something like a phone number. If the silence timeout is too short, the system might mistakenly interpret these pauses as the end of a turn [13].
The underlying issue is that VAD systems can only detect the absence of audio signals. They can’t distinguish between a brief pause where the speaker intends to continue and a true end-of-turn pause. For example, someone might say, "I understand your point, but…" and pause briefly. A basic VAD system could interpret that pause as the end of the conversation, even though the speaker is clearly not finished [13].
"A 500ms pause might mean ‘I’m done’ in one context and ‘I’m thinking’ in another. Simple timeout-based approaches fail here."
- Agent OX [12]
Low-energy sounds, like trailing plosives or soft breaths at the end of words, often fall below the activation threshold for speech detection. Without a proper "hangover" buffer – designed to keep the speech state active for a short time after the signal drops – these subtle sounds can be cut off prematurely. This can lead to interruptions mid-word, even if the overall VAD accuracy seems acceptable [1][5].
How to Configure WebRTC VAD and Silero VAD for Production
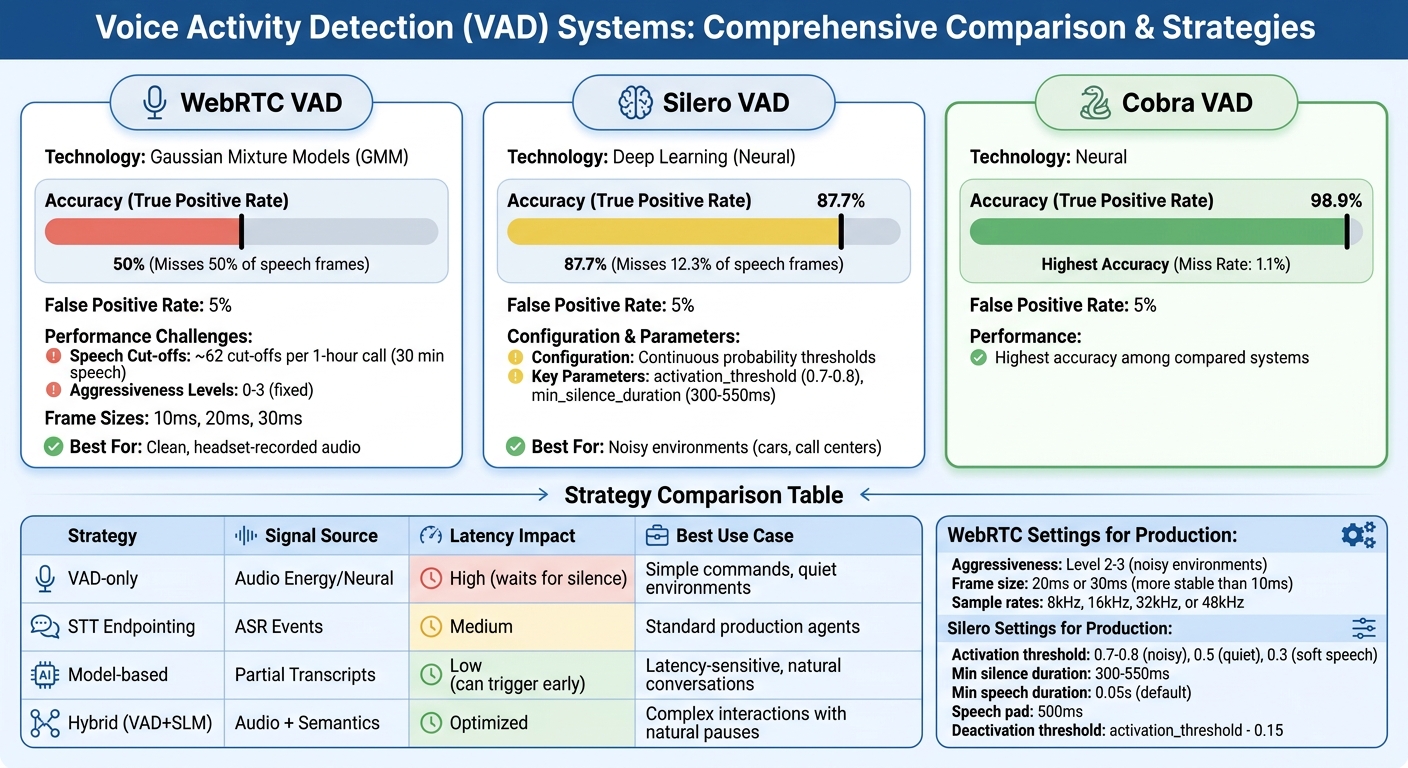
VAD System Performance Comparison: WebRTC vs Silero vs Hybrid Approaches
Fine-tuning Voice Activity Detection (VAD) parameters is essential for ensuring smooth operation in noisy production environments. Below, we’ll explore how to configure WebRTC and Silero VAD effectively for such scenarios.
WebRTC VAD Configuration Parameters
WebRTC VAD relies on Gaussian Mixture Models (GMM) to analyze audio features like energy and spectral patterns. It offers four aggressiveness levels (0–3), where Level 0 is the least aggressive and allows more background noise to pass as speech, while Level 3 aggressively filters out non-speech sounds, often at the risk of cutting off speech prematurely.
Key configuration details for WebRTC VAD include:
- Frame sizes: Accepts 10ms, 20ms, or 30ms frames.
- Sample rates: Supports 8kHz, 16kHz, 32kHz, or 48kHz.
- Recommended settings for production: Use Level 2 or 3 for noisy environments and opt for 20ms or 30ms frames for better stability (10ms frames can be overly sensitive to sudden noise spikes).
The choice of aggressiveness level comes with trade-offs. Higher levels reduce false positives but can lead to speech being cut off. For example, during a simulated 1-hour video call with 30 minutes of speech, WebRTC VAD recorded around 62 speech cut-offs [8]. This makes it significantly less accurate compared to modern deep-learning-based alternatives at similar false positive rates [8].
Silero VAD Configuration Parameters
Unlike WebRTC’s fixed aggressiveness levels, Silero VAD offers more precise control through continuous probability thresholds. Powered by deep learning, it provides parameters like activation_threshold, min_silence_duration, and min_speech_duration for customization.
At the same 5% false positive rate where WebRTC achieves 50% accuracy, Silero VAD delivers a 87.7% true positive rate (TPR) [8]. Here’s how to configure it for optimal results:
-
activation_threshold: Set to 0.7–0.8 in noisy environments like cars or call centers to reduce false triggers [16]. The default of 0.5 works well in quieter settings, while lowering it to 0.3 can capture softer speech but may also activate on noise. -
min_silence_duration: Adjust to 300–550ms to account for natural pauses in speech [15][18]. -
min_speech_duration: Keep at the default value (0.05s) to avoid detecting short noises like coughs or clicks as speech [15][17].
Silero also uses hysteresis with dual thresholds to prevent rapid toggling. For example, the deactivation_threshold is typically set slightly lower than the activation_threshold (e.g., activation_threshold - 0.15) [14][16]. Additionally, setting speech_pad_ms to 500ms helps maintain clean speech boundaries [15][18].
Tracking Performance Metrics in Production
To achieve the best balance between responsiveness and accuracy, it’s crucial to monitor performance metrics regularly. Key metrics to track include:
Instead of relying on a single configuration, evaluate VAD accuracy using Area Under the Curve (AUC), which provides a comprehensive view of detection performance across all thresholds [8]. Metrics should be gathered from real-world usage, not just test environments.
For frequent interruptions, try increasing min_silence_duration by 100ms increments and observe the impact on speech cut-offs and latency. If soft-spoken users are being missed, decrease the activation_threshold by 0.1 and monitor false triggers over the next 100 sessions. These adjustments will help fine-tune the system for diverse production conditions.
Combining Acoustic VAD with LLM-Based Turn Detection
To address the challenges of turn-taking in conversational systems, a hybrid method that integrates acoustic detection with semantic evaluation has shown promise. While Acoustic Voice Activity Detection (VAD) can identify speech and silence, it lacks the ability to assess whether a spoken phrase is semantically complete. For instance, the silence after someone says, "I was walking down the…" is indistinguishable from the pause following a full query like, "What time is the meeting?" This limitation can lead to issues like cutting users off too early or responding when the user hasn’t finished speaking.
The hybrid solution involves a layered pipeline. First, Silero VAD detects speech at the frame level. Then, partial transcripts are analyzed by a semantic evaluator to determine if the statement is complete. If the system detects an incomplete phrase, it extends the silence threshold to 1,500 ms. For direct questions or clearly complete statements, it responds after just 500 ms. This approach minimizes delays – typically between 500 and 2,000 ms – by sometimes responding before the user’s trailing silence ends.
Using Hazard Functions to Model Silence Duration
Instead of treating silence as a simple binary signal (speech vs. no speech), production systems interpret silence as probabilistic evidence of turn completion. Essentially, the longer the pause, the more likely it is that the user has finished speaking. However, this probability is balanced against the semantic completeness of the phrase. This hazard function approach helps avoid cutting users off mid-thought, while still ensuring timely responses when it’s clear the user has finished their turn.
LLM-Based Turn Completion Prediction
Small Language Models (SLMs) with fewer than 10 billion parameters can process partial transcripts in real time, adding less than 500 ms to latency. These models predict whether the next token in a conversation is an end-of-turn marker (e.g., <|im_end|>) or a terminal punctuation mark like a period, question mark, or exclamation point. For example, developers have used SmolLM2-360M-Instruct from Hugging Face to analyze conversations in ChatML format and calculate the likelihood of an end token. In this hybrid system, VAD ensures high recall by detecting any speech pause, while the SLM enhances precision by confirming whether the pause signals a completed turn.
Merging Acoustic and Semantic Confidence Scores
Combining the predictions from LLMs with acoustic confidence levels further improves turn detection accuracy. A semantic probability threshold of 0.03 serves as a baseline, which can be fine-tuned using conversational data. Silence thresholds are adjusted dynamically: shorter for concise commands and longer for complex or ongoing sentences. This adaptability is essential for handling the unpredictable nature of real-world acoustic conditions. Additionally, enabling echo cancellation (via hardware or WebRTC) prevents the agent’s own voice from triggering false detections during barge-in events.
| Strategy | Signal Source | Latency Impact | Best Use Case |
|---|---|---|---|
| VAD-only | Audio Energy/Neural | High (waits for silence) | Simple commands, quiet environments |
| STT Endpointing | ASR Events | Medium | Standard production agents |
| Model-based | Partial Transcripts | Low (can trigger early) | Latency-sensitive, natural conversations |
| Hybrid (VAD+SLM) | Audio + Semantics | Optimized | Complex interactions with natural pauses |
This hybrid approach balances the strengths of acoustic and semantic analysis, creating a system that’s both responsive and precise, even in challenging conversational settings.
Conclusion
Trading Off Response Speed and Detection Accuracy
Finding the right balance between speed and accuracy is no small feat. For instance, adjusting the silence threshold by just 100ms can mean the difference between a responsive agent and one that rudely interrupts users mid-sentence [3][5]. Humans naturally take about 200ms to switch speaking turns [5], but many traditional AI systems introduce delays ranging from 800ms to over 3 seconds. This often makes interactions feel more like operating machinery than having a real conversation [5]. Reducing the threshold to 200–300ms can make responses feel quicker, but it also increases the risk of agents cutting users off mid-thought [6][5].
Why Hybrid Methods Are Necessary
Acoustic Voice Activity Detection (VAD) alone falls short in solving the turn-taking puzzle. It lacks the ability to understand context or assess if a speaker’s thought is complete [2][5]. The real challenge lies in figuring out whether a user has actually finished speaking – something silence detection alone can’t determine. Hybrid methods that combine acoustic detection with semantic analysis powered by large language models (LLMs) are now essential. While acoustic VAD struggles to differentiate between a pause for thinking and a final pause, semantic evaluation bridges this gap [4][5].
These hybrid systems are critical for creating agents that can handle natural conversations effectively.
Continuous Tuning Based on Production Data
Real-world conditions are far messier than controlled lab environments, and user behavior varies widely. For example, older users might require silence thresholds of 600–900ms, while sales agents often thrive with faster thresholds of 200–300ms for more dynamic conversations [3]. To fine-tune your system, track metrics like Interruption Rate, Endpoint Delay, False Barge-in Rate, and User Reprompting Frequency [1][3]. When production failures occur, turn them into learning opportunities by extracting transcripts, audio conditions, and user behaviors that caused the issue [3].
"Voice agents feel ‘fast’ when they manage turns well, not when they chase the last 0.2% WER" – TalkflowAI [1]
Ultimately, tuning efforts should be guided by real user feedback and production data rather than theoretical benchmarks. The strategies outlined in this article – focusing on hybrid methods and continuous optimization – equip voice agents to handle real-world conversations with a natural and responsive feel. By blending acoustic precision with semantic understanding, these agents can deliver the seamless interaction users expect.
FAQs
How do I pick a silence timeout without cutting users off?
When setting a silence timeout, it’s important to account for the natural rhythm of human speech, which includes pauses for thinking or breathing. A fixed duration often falls short, as it doesn’t adapt to these subtle variations. Instead, dynamic thresholds that adjust in real-time based on speech characteristics work better.
Key factors to consider:
- Prosodic cues: Pay attention to natural indicators like pitch drops or audible breathing. These signals can help determine when someone is truly done speaking versus momentarily pausing.
- Buffering: Include a slight delay after the end of speech to avoid cutting someone off mid-thought.
- Environmental sensitivity: Adjust for different noise levels. For example, a noisy setting may require less sensitivity, while a quiet one may need finer adjustments.
- Combining models: Pair acoustic Voice Activity Detection (VAD) with language models. This combination improves accuracy by analyzing both sound patterns and the context of spoken words.
By tailoring the timeout to these elements, you can create a smoother, more natural conversational experience.
What production metrics best capture end-of-speech UX?
When assessing the end-of-speech UX, a few critical metrics come into play:
- Endpointing Accuracy: This measures how effectively the system detects the actual end of a user’s utterance. Precise endpointing ensures smoother interactions.
- Latency to Response: This is the time it takes for the system to respond after the user finishes speaking. Shorter response times contribute to a more natural conversation flow.
It’s also essential to track false-positive interruptions (when the system mistakenly cuts off the user mid-sentence) and false negatives (when it takes too long to recognize that the user has finished speaking). Both of these can disrupt the conversation and negatively affect how responsive the system feels to the user.
When should I add LLM-based turn completion on top of VAD?
When precise turn-taking is essential, incorporating LLM-based turn completion can make a big difference – especially in situations where Voice Activity Detection (VAD) struggles. Issues like pauses, trailing speech, or background noise can make it hard for VAD to pinpoint where one speaker ends and another begins. A hybrid method that combines LLM-based turn completion with VAD significantly boosts accuracy in noisy settings. It also cuts down on false positives, interruptions, and delays, resulting in a smoother and more natural conversational flow. This approach is particularly effective in practical deployments where VAD alone might not perform reliably.
Related Blog Posts
- Why AI Adoption Is Harder in Domain-Heavy Software
- Voice Agent Latency: Where the 2–3 Second Delay Actually Lives in the Pipeline and How to Reduce It
- Voice Agent Production Readiness Checklist: 11 Things to Stress Test Before Enterprise Deployment
- Why Most Agent Framework Benchmarks Don’t Predict What Happens in Production






Leave a Reply