
Why Enterprise Clients Are Now Asking for SLM Options Before Signing Off on Any AI Feature
Huzefa Motiwala May 5, 2026
For enterprise clients, Small Language Models (SLMs) are no longer a nice-to-have – they’re a must-have. Here’s why:
- Regulatory Pressure: Laws like the EU AI Act and GDPR now demand strict data sovereignty and compliance. Enterprises, especially in healthcare, finance, and defense, can’t risk sensitive data leaving their control.
- Data Privacy Concerns: Sharing data with cloud-based AI APIs poses risks like training data leaks or regulatory fines. SLMs eliminate these risks by allowing on-premise or VPC deployment.
- Cost Advantages: Self-hosting SLMs can reduce total ownership costs by up to 55% after 18 months, making them cost-effective for high-volume users.
- Security Demands: Enterprises require guarantees like zero data retention, local processing, and strict compliance documentation to pass security reviews.
If you’re selling AI solutions, offering SLM options tailored to enterprise infrastructure is now essential. Addressing these concerns upfront can make or break the deal.
PodCast Small Language Models SLM Redefining Enterprise AI with Efficiency, Privacy, and Scalability
sbb-itb-51b9a02
Data Privacy Concerns That Drive SLM Requirements
When it comes to enterprise deals, SLM (secure language models) often faces scrutiny due to pressing data privacy concerns. Three major areas dominate these security reviews: training data contamination, regulatory compliance, and exposure through third-party APIs. Tackling these issues head-on can prevent them from stalling your proposal. Let’s dig into the first major concern.
Training Data Usage and Model Contamination Risks
One of the biggest worries is that proprietary data shared with external AI services could end up training models that competitors might later access. A notable example occurred in May 2023 when Samsung banned ChatGPT after employees accidentally leaked sensitive information, including semiconductor source code and internal meeting transcripts, to OpenAI’s servers [9].
Even if vendors promise not to use your data for training purposes, the liability still falls on the enterprise. Under GDPR Article 32, if a cloud provider suffers a breach and customer data leaks, the enterprise – not the provider – bears responsibility. This was underscored in March 2026 when the EU imposed a €50 million fine on an AI company for transferring customer data to U.S.-based cloud services without proper consent [8].
Another concern revolves around AI governance logs, which document access patterns, parameter usage, and testing boundaries. In tightly regulated industries like banking and defense, storing these operational details in third-party clouds is often seen as a compliance violation [4].
Data Residency and Regulatory Compliance
Data residency isn’t just about where data is stored; it’s also about the legal jurisdiction governing it. For instance, the U.S. CLOUD Act allows American law enforcement to access data stored by U.S.-based cloud providers, even if that data resides in EU data centers. This creates a direct conflict with GDPR Article 44 [8][9][10].
Here’s what the numbers say:
- 73% of enterprises rank data privacy and security as their top AI-related risk.
- 77% consider a vendor’s country of origin when making purchasing decisions [9].
- In Europe, 67% of EU enterprises cite data residency as a major hurdle to adopting cloud-based AI [1].
Certain industries face even stricter mandates. For example:
- Healthcare organizations bound by HIPAA see third-party APIs as automatic compliance risks.
- Legal firms avoid external servers to protect attorney-client privilege.
- Financial institutions must adhere to regulations like SEC, FINRA, and India’s RBI data localization rules [2][9].
| Industry | Primary Concern | Why Third-Party APIs Fail |
|---|---|---|
| Healthcare | PHI exposure / HIPAA | Sensitive data is processed externally |
| Legal | Attorney-client privilege | Case documents leave secure firm infrastructure |
| Finance | Data residency (SOC 2, PCI) | Trading strategies risk exposure on external servers |
| Government | FedRAMP compliance | Regulatory hurdles tied to cloud-specific policies |
Third-Party API Access to Sensitive Data
Third-party APIs introduce another layer of risk for enterprises. Every prompt sent to a cloud API is processed on external servers, which is fine for general use cases but problematic for regulated industries. Cloud APIs rely on shared infrastructure, including load balancers and network hops. Even with auto-deletion policies (usually 7–30 days), data remains retrievable via court orders during the retention period [2][11].
The hidden risks don’t stop there. Enterprises often unknowingly send data to embedding APIs, vector database services like Pinecone, or observability platforms such as LangSmith – each creating additional compliance challenges [9].
"Every prompt sent to ChatGPT or Claude is processed on someone else’s servers. For healthcare, legal, finance, and government – this is often a compliance violation."
– FitMyLLM [2]
SLMs offer a way out. Deploying models within your VPC or on-premise infrastructure ensures data stays within your control. Self-hosted H100 inference, for instance, delivers an average latency of 18ms versus 350ms for cloud endpoints. This not only reduces latency by 40% for time-sensitive tasks like risk modeling but also resolves compliance concerns [1].
The shift toward localized solutions is already underway. In March 2023, Italy’s data protection authority temporarily banned ChatGPT over GDPR concerns, prompting OpenAI to implement stricter privacy disclosures before resuming service [9]. Similarly, Grand/Advisense, a European financial services firm serving 700 institutions, achieved full data residency compliance by handling fine-tuning and data processing internally [9].
For founders and sales engineers, the takeaway is simple: map out your data flows, document where logs and prompts are stored, and be prepared to explain how your architecture meets compliance requirements. Vague answers like "somewhere in the cloud" won’t satisfy auditors [6].
How to Structure AI Proposals That Pass Enterprise Security Reviews
If you’re aiming to pass enterprise security reviews, your proposal needs to address the unique challenges posed by AI technologies. Enterprise procurement teams now include AI-specific questionnaires – such as the AI-CAIQ (47 additional questions) and SIG AI domains – on top of standard security checks [12]. This means the security review process for AI features is about 30% larger in scope and can extend the timeline by four to eight weeks [12].
"The questionnaire is asking, in 80 questions, whether you architected the AI feature on the assumption that an enterprise CISO would ever have to approve it." – Tian Pan [12]
To navigate this, specify each AI capability alongside its data control measures. For example, document summarization should emphasize local processing with zero cloud egress [4]. Tie features to concrete guarantees: if you offer chat functionality, clarify that prompt contexts are isolated at the request level. For enterprise clients, highlight dedicated model deployments to prevent data from crossing between tenants [12]. This level of detail connects technical implementation with security compliance, ensuring your proposal aligns with enterprise expectations.
Mapping Features to Privacy and Control Guarantees
It’s critical to clearly state that customer data – such as prompts, completions, and fine-tuning data – will not be used for model training. This is a common source of disputes after contracts are signed [13]. For EU clients, ensure compliance with GDPR and the EU AI Act by geographically pinning inference to their region and preventing cross-border data movement [12][14].
Offer features like configurable retention periods, including a "zero retention" option where prompts are never stored [7][15]. Automated redaction of sensitive data before storage is another key expectation. To address safety concerns, include metrics that quantify resistance to prompt-injection attacks, using benchmarks like the OWASP LLM Top 10 [12]. For example, you might state: "Injection-blocking rate against the OWASP LLM01 evaluation set is 94.2% on v3.1" [12].
| Feature | Privacy Guarantee | Control Mechanism |
|---|---|---|
| Document Summarization | Local processing with zero cloud egress | VPC or on-premise deployment [4] |
| Chat with Docs | Zero data retention | Ephemeral context destruction [7][13] |
| Fine-Tuning | Training data stays in customer VPC | Dedicated model deployment [12] |
These measures are specifically designed to address the concerns enterprise procurement teams frequently raise about data privacy and control.
Required Compliance and Security Documentation
Once your features and controls are clearly defined, back them up with comprehensive compliance and security documentation. SOC 2 Type II is the baseline requirement for most enterprise buyers [12], but additional certifications like ISO/IEC 42001, the first certifiable AI management system standard, are becoming increasingly necessary [12][4].
Prepare an AI Bill of Materials (AI-BOM) – a machine-readable list of datasets, models, and third-party components used in your AI feature [12][17]. This helps address "training data provenance" concerns. You’ll also need data flow diagrams to show where inference occurs geographically and how data crosses borders [12].
For adversarial testing, provide metrics on prompt-injection resistance using published corpora [12][17]. Independent assessments of model bias and harmful-content refusal accuracy are also critical [14][17]. Your AI-specific Data Processing Addendum (DPA) should explicitly forbid training on customer data and define retention periods for prompts and embeddings [13][17].
| Documentation Category | Specific Artifacts Expected by Procurement |
|---|---|
| Compliance Certs | SOC 2 Type II, ISO 27001, ISO 42001, FedRAMP (for Gov) [16][4] |
| Model Governance | AI-BOM, Training Data Provenance, Model Versioning Policy [12][13] |
| Data Privacy | AI-specific DPA, Data Flow Diagrams, Regional Pinning Commitments [12][15] |
| Security Testing | OWASP LLM Top 10 Eval Results, Penetration Test Summaries [12][14] |
| Operational | Incident Response Plan (AI-specific), SLA Commitments [12][16] |
To streamline the process, many vendors are building Trust Centers – online portals (public or NDA-gated) that house all required AI security artifacts. These portals eliminate the need for constant back-and-forth during reviews, speeding up sales cycles [12].
Preparing for Common Security Review Questions
Enterprise security teams will ask detailed questions about where prompts, embeddings, and logs are stored. Be ready with precise answers, including deployment locations and architecture diagrams [6]. Show that customer data is never used for model training – 44% of companies have discovered training data clauses they didn’t explicitly agree to [13].
Flexibility in deployment is another common requirement. Offer options such as VPC deployments for cloud isolation, self-hosted solutions, or on-premise setups for highly regulated environments [4][6]. For hardware-level isolation, include details about confidential computing technologies like Intel TDX or AMD SEV and HSM-backed key management [18].
Enterprise clients also expect model version pinning, allowing them to stay on a specific version for 12–18 months to avoid performance issues during updates [13]. Provide advance notice (90–180 days) before retiring a model version [13][15]. Additionally, consider offering formal latency SLAs (P95) since only 14% of enterprise AI agreements currently include them [13]. While standard AI vendor agreements promise 99.5% uptime, enterprise clients often demand 99.9% or higher, along with financial remedies for downtime [13][18].
Finally, designate someone to handle AI questionnaire responses. This role ensures clear communication between procurement and engineering teams, reducing the risk of delays. About 75% of AI vendors fail to respond on time or completely miss questions during security reviews [12]. Having a dedicated point person can prevent your team from falling into that category.
Technical Options for Meeting Enterprise Hosting Requirements
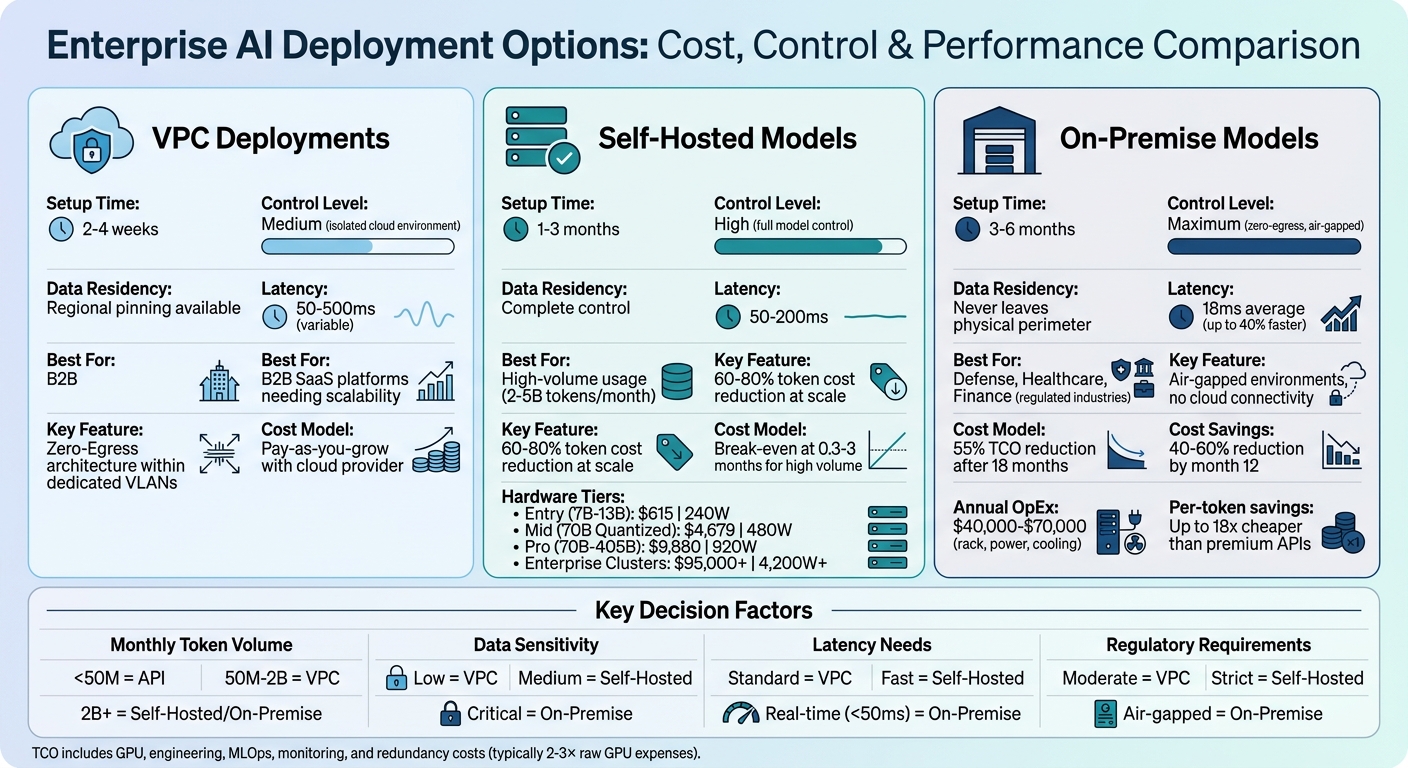
Enterprise AI Deployment Options: VPC vs Self-Hosted vs On-Premise Comparison
After addressing the necessary security reviews, the next step is selecting a deployment architecture that aligns with your client’s control and compliance needs. Whether you choose self-hosted, VPC, or on-premise options, each comes with distinct advantages and cost considerations. Here’s a closer look at these deployment methods.
Self-Hosted Models on Enterprise Infrastructure
Self-hosted models provide enterprises with full control over model weights, versioning, and integrity [7][19]. This means businesses can decide when to update or retire a model version, avoiding disruptions caused by sudden deprecations. For enterprises dealing with unpredictable API changes, this level of control is crucial.
"When enterprises rely on cloud-hosted AI APIs, they are subject to the provider’s versioning lifecycle – a model version can be deprecated, changed, or discontinued with limited notice." – Sonal Dwevedi & Tharun Mathew, KIAA Professional Services [19]
The cost dynamics also shift significantly at scale. Self-hosted models can reduce token costs by 60-80% for high-volume usage compared to public APIs [2]. For many companies, the break-even point for on-premise hardware versus commercial API usage is reached within 0.3 to 3 months [19][2]. Beyond cost savings, this approach directly addresses data privacy requirements.
Small Language Models (SLMs) with 100M–15B parameters are particularly well-suited for self-hosted setups. They can operate efficiently on a single GPU or optimized CPUs, making them ideal for edge or local data center deployments [19]. This is why enterprises increasingly seek SLM options – they offer control and cost benefits without requiring massive infrastructure investments.
VPC Deployments for Cloud-Based Isolation
Virtual Private Cloud (VPC) deployments provide a middle-ground solution, combining cloud scalability with data isolation [19]. This setup is especially popular with B2B SaaS platforms, where tenant-specific adapters like LoRA modules are dynamically loaded at runtime, allowing specialization without duplicating model weights [19].
For enterprises needing scalability alongside stronger data residency guarantees than standard SaaS solutions, VPC deployments offer a compelling option. Within a VPC, client data and derived artifacts (like embeddings and logs) remain isolated, and "Zero-Egress" architectures can be implemented. These architectures ensure models operate within dedicated VLANs or Kubernetes namespaces without outbound internet access [19].
The implementation time for VPC deployments is typically 2-4 weeks [20], making them faster to set up than on-premise solutions while still meeting the needs of most regulated enterprises. This option is ideal for organizations that require elastic scalability but cannot risk the data exposure associated with multi-tenant SaaS APIs.
On-Premise Models for Low-Latency Requirements
On-premise deployments are the go-to choice for enterprises with stringent "Zero-Egress" requirements, where data cannot leave the physical perimeter [19]. This is a critical need for industries like Defense, Healthcare, and Finance, as well as air-gapped environments where no outbound network connections are allowed [4].
"Air-gapped means zero outbound network connections. No telemetry. No update checks. No cloud API calls." – systemprompt.io [4]
Latency is another major advantage. With self-hosted H100 inference, average latency can be as low as 18ms, compared to 350ms for cloud API endpoints [1]. For real-time applications like fraud detection or medical diagnostics, this latency difference is crucial. On-premise setups consistently deliver latency under 50ms, while cloud APIs often fluctuate between 50ms and 500ms [21].
Hardware costs vary based on scale:
- $5,000-$10,000: Single GPU setups for 1-10 users (e.g., NVIDIA RTX 5090)
- $15,000-$35,000: Dual GPU setups for departmental use
- $100,000-$500,000+: Enterprise-scale clusters with 4-8x NVIDIA H100 GPUs [3][20]
Operational costs for rack space, power, and cooling typically range from $40,000-$70,000 per year [21]. Despite these upfront costs, organizations often see a 40-60% cost reduction compared to API usage by the 12th month [20]. For models with 10B+ parameters, the total cost of ownership (TCO) can drop by 55% after 18 months [1]. At scale, running open-weight models on owned hardware can be up to 18x cheaper per million tokens than premium public APIs [22].
How to Price and Scope SLM Features for Enterprise Contracts
Once you’ve chosen a deployment architecture, the next step is figuring out pricing that works for both you and your enterprise customers. Buyers want clear, upfront cost details, while you need to consider the full operational picture – not just hardware expenses.
Pricing Based on Model Size and Usage Volume
A common mistake in pricing self-hosted SLMs is underestimating the total cost of ownership (TCO). GPU costs are just the tip of the iceberg. When you factor in engineering, MLOps, monitoring, and redundancy, TCO often ends up being 2–3× higher than raw GPU expenses [26]. For example, a $10,000/month GPU budget could mean total monthly operational costs of $20,000–$30,000.
The break-even point for self-hosting varies depending on the model size. For a 70B parameter model, self-hosting makes sense when you’re processing more than 2–5 billion tokens monthly. The formula to calculate this is: Break-even months = Initial Investment / (Cloud Monthly Cost - On-Premise Monthly OpEx) [25][23]. Below this threshold, managed APIs remain the more affordable option.
"The self-hosting cost advantage only materializes at scale most companies never reach. Below 50M tokens per day, you are almost certainly better off with an API." – Abhishek Sharma, Head of Engineering at Fordel Studios [26]
For high-volume enterprise contracts, the numbers shift significantly. For instance, a Llama 3.3 70B deployment with full redundancy and operational costs runs about $13,275 per month [26]. Compare this with managed API rates, such as Claude Sonnet 4.6, which charges $3 per 1M input tokens and $15 per 1M output tokens [24]. At scale, self-hosting can become much more appealing.
Defining Scope for Different Deployment Tiers
When scoping deployments, three factors should guide you: monthly query volume, data sensitivity, and latency requirements [23][28]. A tiered approach to hardware packages can help align these needs with costs and performance.
| Tier | Target Models | Estimated System Cost | Power Draw (Load) |
|---|---|---|---|
| Entry | 7B – 13B | $615 | 240W |
| Mid | 70B (Quantized) | $4,679 | 480W |
| Pro | 70B – 405B | $9,880 | 920W |
| Enterprise | Production Clusters | $95,000+ | 4,200W+ |
A hybrid routing strategy can also optimize costs. For example, self-hosting 80% of routine tasks while routing 20% to advanced APIs can balance performance and expenses [25]. This requires budgeting for both on-premise infrastructure and cloud API usage within the same contract.
Don’t overlook personnel costs. Maintaining a self-hosted setup demands about 20% of a senior ML engineer’s time, translating to $30,000–$50,000 per year in hidden labor costs [25][26]. When planning, allocate 0.25–1.0 FTE for infrastructure management [28].
These tiered packages are designed to meet a variety of enterprise demands while maintaining compliance with SLM requirements.
Structuring Milestone-Based Contracts
Once pricing and scope are set, structuring milestone-based contracts ensures accountability and measurable outcomes. Enterprise clients often prefer payment schedules linked to specific results rather than just deliverables. The most effective contracts break down into four phases: Objective Definition/Audit, Proof-of-Concept (POC), Mid-Scale Deployment, and Full-Scale Integration [27].
Start with a 90-day pilot focused on a low-risk, high-value use case, such as internal knowledge search. This phase should include clear success metrics and a curated "Golden Set" of 200–500 examples [7]. If the model doesn’t perform well on this set, it shouldn’t move to the next phase. A typical POC takes 4–8 weeks, while full production deployment can take 3–6 months [5].
Enterprise contracts often begin with a $250,000 annual commitment [15]. Larger commitments unlock discounts: 20–40% off list prices for annual volumes and up to 25–45% for multi-year cloud commitments [15]. To ensure value, structure contracts with adoption-indexed payments, tying payments to actual usage or minimum guarantees [15]. This approach aligns payments with performance and reduces risk for the client.
Lastly, include technology refresh provisions in two-year contracts. These clauses allow for seamless upgrades to next-gen models without penalties [15], ensuring both parties stay ahead in a rapidly evolving AI landscape.
Conclusion: Responding to Enterprise AI Procurement Requirements
What Founders and Sales Engineers Need to Remember
In today’s market, enterprise AI procurement revolves around a few key expectations: data privacy, hosting control, and model transparency. These are no longer optional; they’re the baseline. When presenting your solutions, make sure to offer deployment options like VPC, on-premise, or self-hosted setups [5]. These options directly address the concerns enterprises have about safeguarding their data and maintaining control over their AI systems.
Every AI feature you offer should come with clear privacy guarantees. For example, highlight commitments like zero data retention, no use of customer content for training, and full audit rights. Also, include clauses for 90-day deprecation and portability, allowing clients to extract fine-tuned model weights in standard formats [15].
"The winning private LLM offer is rarely the largest model. It is the smallest model that can be governed, measured, and sold with confidence." – smartstorage.host [7]
When pricing your AI solutions, transparency is critical. Make sure to factor in all operational costs, including expenses for GPUs, monitoring, MLOps, and personnel. These costs typically make up more than 70% of total expenditures [5]. For businesses managing over 2 million tokens daily, self-hosting can achieve cost parity with API-based solutions [5].
Adapting to Changing Enterprise Expectations
As enterprises become more informed and cautious, their expectations are rapidly evolving. By 2026, 80% of Chief Procurement Officers are expected to prioritize AI investments, and 94% of procurement executives report using generative AI weekly [29]. This shift means buyers are scrutinizing solutions more closely than ever.
To stay competitive, prioritize data sovereignty, particularly for industries like finance, healthcare, and defense. With regulations like the EU AI Act (effective August 2025) and stricter GDPR enforcement on the horizon, vendors must include explicit cooperation clauses for audits and conformity assessments in their contracts [15]. Aligning with these regulatory frameworks is no longer optional – it’s a necessity. Additionally, the market is moving toward human-in-the-lead frameworks, emphasizing that humans, not AI, should make critical decisions [14].
Position yourself as a trusted partner by offering a flexible, tiered approach. For example:
- Use API access for low-volume, less-sensitive applications.
- Provide VPC options for workloads with moderate sensitivity.
- Offer on-premise solutions for high-risk, mission-critical operations.
This adaptability will help you meet the growing and varied demands of enterprise clients, ensuring you remain a step ahead in a competitive landscape.
FAQs
How do I prove to an enterprise that their data won’t be used for model training?
To reassure businesses that their data remains protected and won’t be used for model training, it’s important to highlight that many AI providers have safeguards in place to prevent such practices. Offering options like self-hosted models, VPC (Virtual Private Cloud) deployments, or on-premise solutions ensures that data remains fully under the client’s control.
Additionally, building trust involves setting clear contractual agreements that explicitly outline data usage policies. Emphasizing compliance certifications, such as SOC 2, demonstrates adherence to strict security standards. Transparency about how data is handled and the security measures in place further reinforces confidence and showcases a commitment to protecting client data.
What deployment option should I offer first: VPC, self-hosted, or on-prem?
Start with a self-hosted solution if maintaining control over data privacy, security, and governance is a top priority. This option aligns well with enterprises that have stringent security needs. For secure integration within private cloud environments, explore VPC deployment, which offers a balance of security and flexibility. If the situation demands strict adherence to regulatory compliance, opt for on-premises deployment – though keep in mind that this choice comes with added complexity and higher infrastructure costs. Choose the deployment model that best matches the enterprise’s unique needs and priorities.
When does self-hosting an SLM actually become cheaper than an API?
When you self-host a serverless language model (SLM), it becomes more cost-effective than relying on an API if the combined costs of infrastructure, computing power, and maintenance fall below the ongoing expenses of API usage. This shift usually occurs under high usage scenarios – typically exceeding 50 million tokens per day – or after 18 months of large-scale deployment. Cost efficiency improves further when infrastructure and hardware are fine-tuned for optimal performance. In short, high-volume usage or long-term deployments are the main drivers of savings.
Related Blog Posts
- Building an AI Feature with Open-Source Models: Cost & Risk Breakdown
- Self-Hosted AI for Construction Firms: Architecture, Costs, and Compliance in 2025
- The Engineering Challenges Behind Shipping AI-Powered Features
- Self-Hosted SLMs for Regulated Industries: Architecture, Cost, and Compliance Trade-offs We’ve Navigated
Huzefa Motiwala
Huzefa Motiwala is a co-founder of AlterSquare, an application-layer partner that helps SaaS and tech-led companies stabilise, modernise, and extend complex systems without breaking what already works. He comes at software from design and frontend, with a focus on data-heavy interfaces and on getting real teams to actually adopt what gets built — not just ship it. He writes about working in fragile, high-stakes codebases: incremental change over risky rewrites, UX and technical debt, and embedding AI into real workflows.







Leave a Reply