
The GPT-4 to SLM Migration Decision: When Smaller Models Are Good Enough and When They Will Cost You
Huzefa Motiwala May 6, 2026
AI costs can spiral out of control if you’re using GPT-4 for tasks that don’t need its advanced capabilities. Many companies overspend by up to 10x on LLMs when cheaper, smaller language models (SLMs) could handle simpler tasks just as well. Here’s the key takeaway: Use GPT-4 for complex reasoning or nuanced instructions, but migrate predictable, structured tasks – like classification or templated content generation – to SLMs. The result? Savings of up to 97% without sacrificing performance for those tasks.
Key Insights:
- When to Use SLMs: Tasks like data extraction, ticket classification, or templated responses are ideal for SLMs. These models are faster and much cheaper.
- When to Stick with GPT-4: Complex reasoning, ambiguous instructions, or multilingual support often require GPT-4’s advanced capabilities.
- Cost Savings: Switching to SLMs can reduce costs by 60–97%, especially for high-volume workflows.
- Hybrid Approach: Many companies save the most by routing simple tasks to SLMs while reserving GPT-4 for complex queries.
- Challenges with SLMs: SLMs can struggle with detailed instructions, low-resource languages, or tasks requiring extended context.
The decision boils down to matching the right model to the right task. For high-volume, predictable workloads, SLMs can deliver massive cost reductions. But for complex or critical tasks, GPT-4 remains the better choice. Smart routing and careful monitoring can help you find the balance between cost and performance.
AI models compared: GPT-4o vs GPT-4o mini
sbb-itb-51b9a02
When GPT-4 Is Overkill for Your Use Case
Not every task requires the advanced reasoning capabilities of GPT-4. Many use cases are better suited to simpler models, especially when the task relies more on pattern matching than problem solving. If your workload can be addressed with 50–200 well-crafted examples and fits within 4,000–8,000 tokens, it’s a prime candidate for a smaller language model (SLM) [5][8].
Structured Extraction and Classification
Tasks like extracting names, dates, or product codes from documents, or classifying support tickets, often don’t need GPT-4’s vast general knowledge. These are narrow, predictable tasks with clear output formats. For example, in November 2025, Reliable Data Engineering replaced GPT-4 with a fine-tuned Llama 2 (13B) model for classifying support tickets and analyzing sentiment. The results? They handled 50,000 daily calls with 96% accuracy, outperforming GPT-4’s 94% on the same dataset, while slashing monthly costs from $40,125 to $15,109 – a dramatic 60% reduction [9].
"The right question is never ‘what is the most powerful model?’ – it is ‘what is the smallest model that solves this task reliably?’" – TunerLabs Engineering [1]
SLMs shine in tasks like entity extraction, intent classification, sentiment analysis, and content moderation. Their focused design allows them to excel in specific domains without the overhead of general knowledge [1][9]. For classification tasks, a fine-tuned Llama-13B costs about $0.00002 per call, compared to GPT-4’s $0.008 per call – a staggering 400× cost difference [9].
When tasks have predictable outputs, it’s often more effective to switch to an SLM.
Templated Content Generation
For tasks like generating FAQ responses, checking order statuses, processing returns, or drafting simple email replies, GPT-4’s advanced features are unnecessary. These tasks rely on template-based outputs, where consistency is more important than creativity. SLMs often outperform here by offering a more uniform style and fewer irrelevant outputs, as they aren’t distracted by unrelated general knowledge [5][1].
In early 2026, developer Salih Yildirim transitioned document classification (2,000 calls/day) and structured data extraction (1,500 calls/day) from OpenAI’s GPT-4 to a local Mistral 7B model running on vLLM. This shift reduced monthly costs from $380 to under $80, achieving nearly the same quality for well-defined tasks while cutting total expenses by 59%, even after factoring in GPU server costs [10].
The Cost of Using GPT-4 Where You Don’t Need It
As of May 2026, GPT-4o pricing is $2.50 per million input tokens and $10.00 per million output tokens [5]. For a classification task requiring 500 input and 50 output tokens, GPT-4 costs around $0.00175 per query, which scales to $1,750 per million queries. In contrast, a self-hosted SLM can perform the same task for about $11 per million queries [5].
The cost gap widens for tasks with high output demands, such as generating summaries, reports, or templated responses. In these cases, GPT-4’s $10.00 per million output tokens can quickly dominate costs [2]. For high-volume workflows, especially those that are output-heavy, switching to an SLM offers significant savings.
These examples highlight how to identify tasks where GPT-4 adds little value, paving the way for a deeper comparison of costs and capabilities in the next sections.
Where SLMs Fall Short
SLMs work well for simple, predictable tasks, but they falter when faced with more complex reasoning, ambiguous instructions, or languages with limited training data. These limitations are important to consider before shifting away from GPT-4-class models.
Complex Reasoning and Multi-Step Logic
SLMs hit a wall when tasks demand multiple steps of logic or require integrating knowledge from different areas [12]. For instance, evaluating how a regulatory change might affect supply chain costs in a specific region is often beyond their capabilities [8]. These models excel at tasks they’ve seen before but struggle with unfamiliar problems that lack a predefined reasoning path [8][12].
"Small models are specialists, not generalists. Match them to well-scoped tasks… Don’t ask them to reason through complex, open-ended problems." – Amit Upadhyay, Staff Engineer [12]
On benchmarks like MMLU, SLMs lag 10–20 points behind top-tier models [8]. Many advanced capabilities – like following detailed instructions or using tools effectively – are typically seen only in models with 70 billion parameters or more [11]. Additionally, their performance drops sharply when processing large amounts of text. While GPT-4 can handle over 200,000 tokens while maintaining coherence, SLMs struggle with anything beyond 8,000–32,000 tokens [6][12]. This makes them less reliable for tasks requiring nuanced reasoning or extended context.
Following Ambiguous or Detailed Instructions
SLMs require highly structured instructions to perform well [14]. Unlike GPT-4, which can infer user intent from vague queries, smaller models often fail to grasp the meaning without clear guidance [1]. Even the format of the prompt matters – using a suboptimal template (like ChatML versus Llama format) can further weaken their already limited reasoning abilities [12].
In a six-week study, pipeline runs recorded 23 failures due to subtle inconsistencies, such as switching between dataset_source and datasetSource [13]. While models like Qwen2.5-7B and Mistral 7B achieved 90–95% accuracy on annotated document tasks, their performance dropped significantly when handling ambiguous documents, especially when compared to GPT-4 [13]. Newer versions like GPT-4.1 and GPT-4.5-preview maintained regression test pass rates of 98% and 97.3%, respectively, thanks to their ability to infer implicit rules more reliably [14].
"The cost of one GPT-4o call is still less than the cost of one wrong answer." – Amit Upadhyay, Staff Engineer [12]
These challenges become even more pronounced when dealing with low-resource languages.
Low-Resource Language Support
GPT-4 benefits from training on more diverse datasets than SLMs [2][15]. There’s a noticeable drop in quality between 70B+ models and smaller 7B-class models, especially for critical multilingual tasks. For customer-facing or business-essential applications, 70B is often the baseline to avoid unacceptable error rates [15].
"There is a clear quality cliff between 7B and 70B models for production tasks. For anything customer-facing or business-critical, plan around 70B as your minimum." – iBuidl Research [15]
Even among larger models, performance varies depending on language focus. For example, Qwen2.5 72B performs exceptionally well in Chinese, Japanese, and Korean, while Meta Llama 3.3 70B achieves around 85% of GPT-4o’s quality on instruction-following and coding tasks as of March 2026 [15]. Companies relying solely on SLMs for global SaaS applications risk delivering a subpar experience in non-primary markets. This can lead to higher latency and user frustration due to inconsistent reasoning or formatting in languages with less training data [2].
Cost Modeling: GPT-4 vs. Self-Hosted SLMs
This section breaks down the cost differences between GPT-4 APIs and self-hosted SLMs, focusing on how these options compare in terms of expenses and scalability. For context, self-hosted SLM inference costs can drop as low as $0.17 per million tokens, while GPT-4’s rate is $2.50 per million tokens for input [17].
Per-Query Costs at Scale
For smaller workloads – like 1 million tokens per day (around 2,000 queries daily at 500 tokens each) – GPT-4o Mini costs about $225 per month, compared to $184 per month for GPU usage on dedicated hardware (e.g., Hetzner GEX44). However, the required setup time (usually 2–4 weeks) often makes the API more appealing for these volumes [6].
As query volumes grow, the financial equation changes. The tipping point typically occurs when annual API costs exceed $200,000–$500,000 or daily token usage surpasses 50 million tokens [16]. Below this threshold, the fixed costs of GPUs rarely justify the switch. For example, a FinTech mobile trading app faced a cost increase from $12,000 to $47,000 per month using GPT-4o Mini until they adopted a hybrid approach. By routing 70% of requests to Claude Haiku and using a self-hosted 7B model for bulk tasks, they slashed monthly costs to $8,000 while maintaining strong customer satisfaction [18].
"The self-hosting cost advantage only materializes at scale most companies never reach. Below 50M tokens per day, you are almost certainly better off with an API." – Abhishek Sharma, Head of Engineering, Fordel Studios [16]
Engineering Time and Maintenance Overhead
GPU costs make up just 40–50% of total expenses [16]. Managing a production-grade setup typically requires 0.5 full-time equivalent (FTE) for tasks like GPU operations, vLLM tuning, and capacity planning [7]. Maintenance for a mid-sized internal assistant averages 15 hours per month, translating to roughly $3,450 monthly at a rate of $230 per hour [19]. Additional overhead can inflate costs by another 30–50% on top of GPU expenses [7].
Reliability adds complexity. To avoid downtime, companies often maintain a warm replica in a secondary availability zone, effectively doubling baseline costs [7]. Moreover, self-hosted models can have load times of 60–180 seconds, requiring "always-warm" replicas to reduce latency. Outbound data transfer costs – typically $0.09 per GB – can add $200 to $1,000 monthly at high volumes. Compliance with standards like HIPAA or PCI DSS can further increase annual expenses by 5–15% due to audits and additional staffing [18].
At low GPU utilization (around 20%), self-hosting offers minimal savings compared to APIs. However, at 60–80% utilization, costs can drop by as much as threefold. Unlike APIs, which charge only for active usage, GPUs incur fixed costs regardless of workload, making self-hosting less economical for bursty or low-utilization scenarios [7][18].
12-Month Total Cost of Ownership
A deeper look at total cost of ownership (TCO) highlights the broader financial picture. For a high-volume workload of 1 million queries per day (500 tokens per query, totaling 15 billion tokens monthly), the GPT-4o API would cost $2.25 million annually. In contrast, a self-hosted 70B model incurs about $7,650 in GPU costs monthly. However, when factoring in failover instances, networking, monitoring, and engineering resources, the monthly total rises to approximately $13,275 [16]. A hybrid strategy – routing 85% of routine tasks to SLMs and using frontier APIs for more complex queries – can bring annual TCO down to around $360,000, offering a balance between cost and performance [16].
| Cost Component | GPT-4 API | Self-Hosted SLM (70B) |
|---|---|---|
| Direct Cost | Pay-per-token ($12.50 per million) | Fixed GPU lease ($5,000–$7,500/month) |
| Engineering | Minimal (API integration) | High ($3,000–$8,000/month) |
| Infrastructure | None | Significant (networking, failover) |
| Scalability | Instant (subject to rate limits) | Requires manual provisioning |
| Data Privacy | Limited (third-party exposure) | Full data control |
In January 2026, AT&T collaborated with Mistral AI to deploy fine-tuned SLMs for customer support and document processing. Spearheaded by Chief Data Officer Andy Markus, this initiative achieved a 90% cost reduction and 70% latency improvement compared to earlier cloud-based LLM setups [17]. Their architecture utilized an "intent router" to handle 80–90% of routine tasks with local SLMs, reserving APIs for more complex operations [2][4].
"Self-hosting AI inference is like running your own email server. You can do it… But for most organizations, the question is not whether you can – it is whether you should." – Abhishek Sharma, Head of Engineering, Fordel Studios [16]
These cost insights lay the groundwork for the migration decision matrix discussed in the next section.
Migration Decision Matrix: Task Type and Query Volume
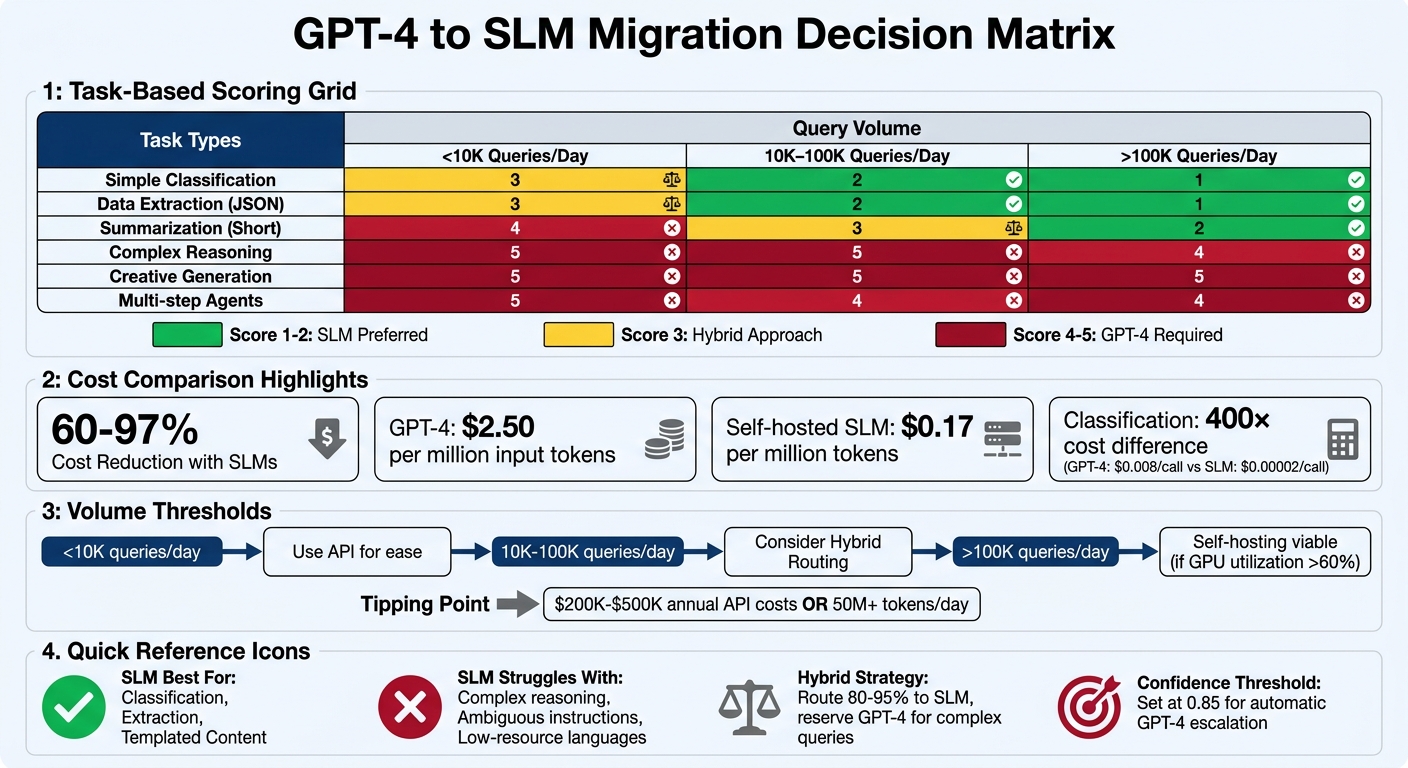
GPT-4 vs SLM Cost Comparison and Migration Decision Matrix
For most SaaS applications, around 80% of queries fall under simple tasks, making them a natural fit for SLMs [5]. This breakdown helps in pairing task types with the right model capabilities.
Matching Task Types to Model Capabilities
The first step is to categorize all API calls in your system. If a task can be effectively represented with 200 examples and fits within 4,000 tokens, it’s a strong candidate for SLM migration [5]. Tasks like intent classification, entity extraction, and sentiment analysis usually score a 1 on the SLM fit scale, meaning SLMs are the preferred option. On the other hand, tasks involving complex reasoning, creative writing, or long-context synthesis (exceeding 32,000 tokens) often score a 5, indicating GPT-4 is necessary [5].
To balance quality and cost, a hybrid routing architecture can be implemented. In this setup, straightforward queries are handled by SLMs, while ambiguous cases – those with a confidence score below 0.85 – are escalated to GPT-4 [5]. This approach has been proven effective; for instance, a case study from early 2026 reported a 97% cost reduction using this method [5].
How Query Volume Changes the Equation
Query volume significantly impacts the choice of infrastructure. For systems handling fewer than 10,000 queries per day, managed APIs are often the most convenient option. As query volume grows to the 10,000–100,000 range, a hybrid routing strategy becomes more appealing. Here, SLMs manage the bulk of simple tasks, while GPT-4 handles exceptions.
For systems processing over 100,000 queries per day, self-hosting can become more cost-effective for routine tasks – provided GPU utilization remains above 60–70% [6][20]. Before committing to self-hosting, it’s wise to test whether cost-optimized APIs like GPT-4o-mini (priced at approximately $0.15 per million input tokens) can meet your quality standards [11].
Decision Matrix Table
The table below combines task types and query volumes to help guide migration decisions:
| Task Type | <10K Queries/Day | 10K–100K Queries/Day | >100K Queries/Day |
|---|---|---|---|
| Simple Classification | 3 (API for ease) | 2 (SLM for cost) | 1 (SLM required) |
| Data Extraction (JSON) | 3 (API for ease) | 2 (SLM for cost) | 1 (SLM required) |
| Summarization (Short) | 4 (API for quality) | 3 (Hybrid) | 2 (SLM preferred) |
| Complex Reasoning | 5 (GPT-4) | 5 (GPT-4) | 4 (Hybrid/Distilled) |
| Creative Generation | 5 (GPT-4) | 5 (GPT-4) | 5 (GPT-4) |
| Multi-step Agents | 5 (GPT-4) | 4 (Hybrid) | 4 (Hybrid) |
Scoring: 1 (SLM Preferred) to 5 (GPT-4 Required)
"The right question is never ‘what is the most powerful model?’ – it is ‘what is the smallest model that solves this task reliably?’" – TunerLabs Engineering [1]
Post-Migration Monitoring and Failure Patterns
Once you’ve made the leap to a new system using your migration decision matrix, keeping a close eye on performance is crucial. Post-migration monitoring helps identify silent failures early, ensuring that any cost savings don’t come at the expense of functionality or quality.
Common Failure Patterns After Migration
After migration, certain issues can creep in unnoticed. For instance, classification accuracy might quietly drop from 94% to 87%, leaving users to discover the problem first[10]. Prompt incompatibility is another frequent issue. Prompts that worked perfectly with GPT-4 might fail with smaller language models (SLMs) like Mistral 7B, which often need more explicit instructions to deliver accurate results[10].
In April 2026, software engineer Salih Yildirim shared his experience transitioning to Mistral 7B. He noticed the model struggled with automated tasks, such as multi-step tool-calling, frequently hallucinating parameters or selecting the wrong tools. To address cold start delays, he implemented a "warmup probe" by sending a dummy request at container startup, which eliminated latency issues[10].
"Model updates can silently drop classification from 94% to 87% and you won’t notice until users complain." – Salih Yildirim, Full Stack Software Engineer[10]
Formatting inconsistencies are another headache. While SLMs are often more deterministic than GPT-4 when using seeded inference, they can still switch between formats like camelCase and snake_case unless explicitly constrained[13].
Setting Up Confidence Thresholds
To ensure reliability, configure your SLM to output a confidence score with each response. If the score dips below a defined threshold – commonly set at 0.85 – the system should automatically escalate the query to GPT-4[1].
In April 2026, developer Benjamin Nweke replaced a GPT-4-based metadata extraction pipeline with Qwen2.5-7B-Instruct. By using seeded inference (seed: 42) and a strict system prompt, he achieved 100% consistency across multiple runs. His previous GPT-4 setup had a 6% failure rate due to inconsistent JSON formatting, but the SLM eliminated these errors through rigid output constraints[13].
Before fully implementing confidence-based routing, test it in shadow mode for a week to fine-tune the thresholds. Log every fallback trigger – whether due to "low_confidence", "schema_fail", or "timeout" – to refine your routing policies and avoid hidden retry loops[22].
Once the thresholds are calibrated, integrate them into a dynamic routing system for real-time fallback handling.
Using vLLM for Dynamic Routing
With fallback triggers in place, a tiered routing system using vLLM can balance efficiency and reliability. This architecture routes simpler, repetitive tasks like classification and extraction to SLMs, while reserving complex reasoning tasks for GPT-4[24].
In April 2026, Salih Yildirim designed a hybrid routing system combining vLLM and Mistral 7B. This reduced his monthly costs from $380 to $155 by sending straightforward tasks to the local SLM and reserving tool-calling chains for GPT-4. To address common failure patterns, he added a warmup probe to eliminate 30-second cold starts and built a routing layer that automatically fell back to GPT-4o-mini if the local GPU went offline[10].
"A 7B model fumbling a tool-calling chain costs more in debugging time than the API bill." – Salih Yildirim, Full Stack Software Engineer[10]
Set fallback triggers for scenarios like low confidence, schema failures, timeouts, or ambiguous intent. For fixed outputs, enforce schema validation (e.g., with Pydantic) to prompt immediate retries[22][23]. Additionally, monitor metrics like escalation rate (how often requests revert to GPT-4), latency, and throughput[21]. To avoid runaway costs, set hard monthly spend alerts at 80% of your budget to catch excessive fallback escalations early[11].
Conclusion
Switching from GPT-4 to SLMs isn’t an all-or-nothing decision. It’s about matching each task to the model that fits it best. As outlined, the choice between GPT-4 and SLMs hinges on factors like task complexity, volume, and ongoing performance tracking. For tasks like structured data extraction, classification, or high-volume templated generation, SLMs can often match GPT-4’s quality while significantly reducing costs. On the other hand, GPT-4 is better suited for complex reasoning, intricate instructions, or support for less common languages.
"The question isn’t ‘API or self-hosted?’ It’s ‘what’s the right mix for your specific constraints?’" – Prashant Dudami, AI/ML Architect [3]
This decision-making process shapes both cost strategies and performance expectations. Self-hosting becomes practical when GPU usage reaches 60–80%, typically when processing between 100 and 500 million tokens monthly. This calculation also factors in engineering overhead, estimated at 0.25 to 1.0 full-time equivalents for managing the infrastructure [3][7]. For many teams, a hybrid approach works best: directing 80–95% of predictable tasks to an SLM while reserving GPT-4 for more complex, less frequent queries [8][1].
Post-migration monitoring is critical to avoid silent issues like unnoticed drops in classification accuracy. Confidence thresholds should be set at 0.85, with automatic escalation to GPT-4 for tasks where the SLM lacks sufficient confidence [1]. Keeping an eye on metrics like escalation rates and response times will help catch problems early.
Before fully committing to SLMs, audit your traffic, calculate total ownership costs (including staffing), and test key prompts on the SLM [6]. If SLM accuracy is more than 10% lower than GPT-4, the savings may not justify the performance trade-offs [6]. Ultimately, balancing task needs, costs, and performance is the cornerstone of a successful migration plan.
FAQs
How do I know which calls are safe to move off GPT-4?
When considering migrating tasks from GPT-4 to smaller language models (SLMs), focus on areas where SLMs tend to excel. These include tasks such as structured data extraction, classification, and templated text generation. These tasks typically require less complexity, making them well-suited for smaller models.
Before making the switch, it’s essential to benchmark these smaller models to ensure they meet your specific requirements for both accuracy and latency.
However, some tasks are best left to GPT-4. For example, avoid migrating tasks that rely on complex reasoning, following nuanced instructions, or supporting low-resource languages, as SLMs generally struggle in these areas.
Finally, always validate the results after migration and keep an eye out for potential failure patterns to ensure the new setup is reliable.
What’s the simplest way to route low-confidence SLM outputs to GPT-4?
The easiest method is to implement a routing framework that evaluates the SLM’s confidence level. By setting a confidence threshold, you can determine when to involve GPT-4. If the confidence score drops below this threshold, the output is redirected to GPT-4 for additional processing. This way, the SLM efficiently manages straightforward tasks, while GPT-4 steps in for more uncertain cases, striking a balance between cost and performance.
When does self-hosting an SLM actually beat API costs after engineering overhead?
Self-hosting a Serverless Language Model (SLM) makes financial sense when the cost savings from running inferences at large scales surpass the associated engineering and operational costs. This tipping point is usually reached when monthly token usage consistently falls between 100–500 million tokens and GPU utilization stays around 70%. Keeping GPUs active at this level helps prevent expensive idle time. For smaller-scale operations, sticking with API services tends to be more cost-efficient, as fixed costs and the challenges of maintaining infrastructure can outweigh the benefits of self-hosting.
Related Blog Posts
- Phi-4 vs Gemma 3 vs Mistral Small: A Practical Benchmark for the Enterprise Use Cases That Actually Matter
- Self-Hosted SLMs for Regulated Industries: Architecture, Cost, and Compliance Trade-offs We’ve Navigated
- Why Enterprise Clients Are Now Asking for SLM Options Before Signing Off on Any AI Feature
- On-Device AI With SLMs: The Latency and Memory Trade-offs Nobody Benchmarks Honestly
Huzefa Motiwala
Huzefa Motiwala is a co-founder of AlterSquare, an application-layer partner that helps SaaS and tech-led companies stabilise, modernise, and extend complex systems without breaking what already works. He comes at software from design and frontend, with a focus on data-heavy interfaces and on getting real teams to actually adopt what gets built — not just ship it. He writes about working in fragile, high-stakes codebases: incremental change over risky rewrites, UX and technical debt, and embedding AI into real workflows.







Leave a Reply