
Agent Memory Architecture: Why Your Design Decision at Week One Determines Your Ceiling at Scale
Huzefa Motiwala April 27, 2026
When building AI agents, memory architecture is critical from day one. Skipping this step early can lead to costly scaling issues, like repeating errors or contradicting itself during conversations. Klarna’s AI in 2024 is a prime example – it excelled initially but faced major problems due to poor memory design.
Here’s the core takeaway: Memory is not just a feature; it’s the backbone of an agent’s long-term performance. AI agents rely on four memory types:
- In-Context Memory: Fast but expensive, limited by token capacity and high costs.
- External Vector Memory: Scalable and cost-effective, but retrieval errors can occur without hybrid strategies.
- Episodic Memory: Tracks interaction history, ideal for continuity but requires careful curation.
- Semantic Memory: Stores structured facts, resolving contradictions but complex to implement.
Early decisions about memory – like choosing a monolithic setup or relying only on vectors – can lock you into inefficiencies that are hard to fix later. A tiered memory system (e.g., combining in-context, vector, episodic, and semantic layers) ensures scalability, lower costs, and better performance.
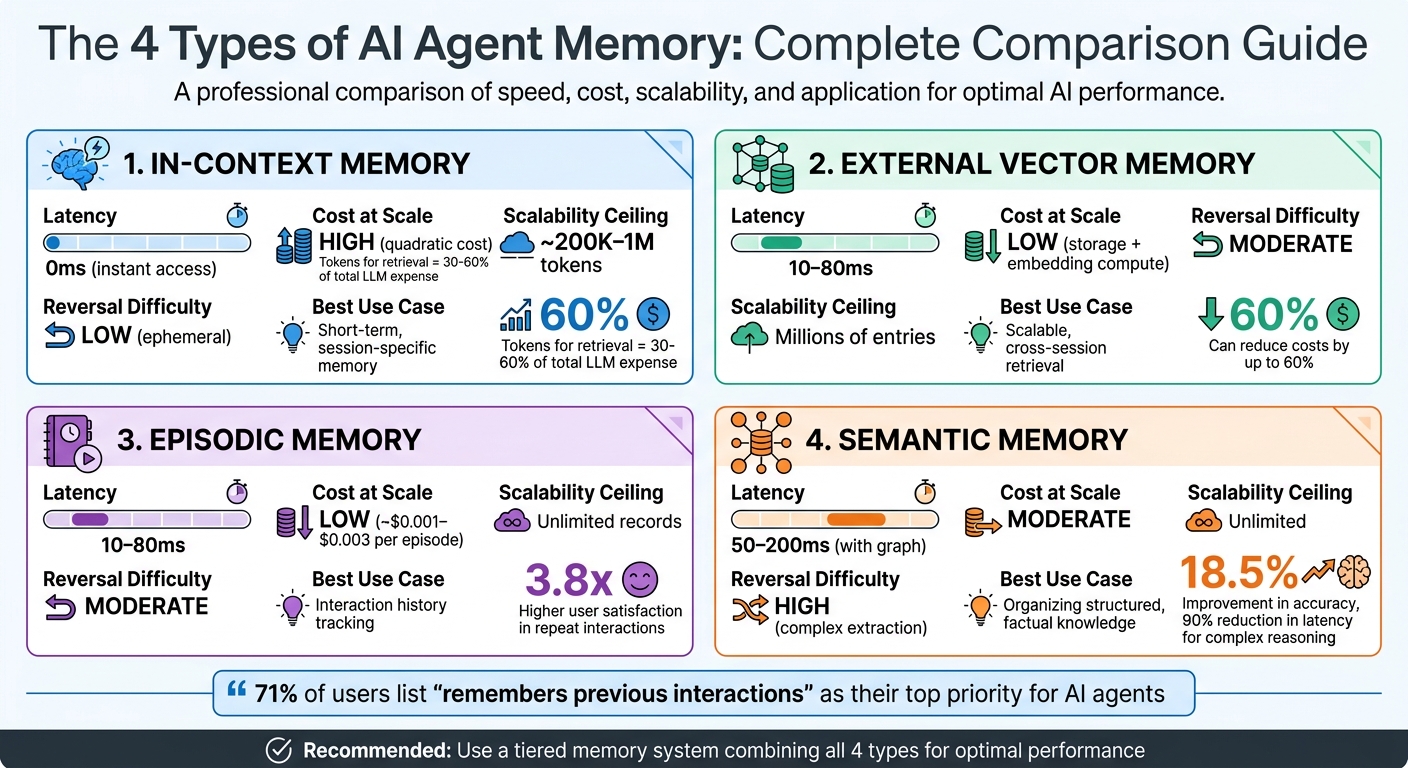
Quick Comparison of Memory Types
| Memory Type | Latency | Cost at Scale | Scalability Ceiling | Reversal Difficulty | Best Use Case |
|---|---|---|---|---|---|
| In-Context | 0ms | High | ~200K–1M tokens | Low | Short-term, session-specific memory |
| External Vector | 10–80ms | Low | Millions of entries | Moderate | Scalable, cross-session retrieval |
| Episodic | 10–80ms | Low | Unlimited records | Moderate | Interaction history tracking |
| Semantic | 50–200ms | Moderate | Unlimited | High | Organizing structured, factual knowledge |
The key to success? Start with a tiered memory framework and avoid locking into a single memory type. This ensures your AI agent can handle future growth without expensive rework.
AI Agent Memory Types: Performance, Cost and Scalability Comparison
Architecting Agent Memory: Principles, Patterns, and Best Practices – Richmond Alake, MongoDB
sbb-itb-51b9a02
The 4 Types of Agent Memory
Your AI agent relies on four distinct memory systems, each offering a unique balance of speed, capacity, and persistence.
In-context memory works like the agent’s short-term memory, holding the current conversation, system prompts, and immediate tool outputs within the language model’s context window. External vector memory uses embedding models to expand the agent’s reach beyond the immediate context, managing millions of records efficiently. Episodic memory serves as a chronological log, storing past interactions along with timestamps – what happened, when, and with whom. Meanwhile, semantic memory organizes raw experiences into structured facts, often using knowledge graphs or databases to ensure consistency across sessions.
Interestingly, 71% of users list "remembers previous interactions" as their top priority for AI agents [11]. While in-context memory offers instant access, it comes with high token costs. On the other hand, external vector, episodic, and semantic memory systems scale to millions of records but introduce retrieval latencies ranging from 10ms to 200ms [4][9][11]. The architectural decisions you make early on will dictate how these trade-offs impact your system in the long run. Let’s break down each memory type.
In-Context Memory: Fast but Costly
In-context memory includes everything the language model can "see" during a session – system prompts, conversation history, retrieved facts, and tool outputs. It operates without latency but has a high token cost and struggles with large amounts of content [4][9].
Even with advanced models supporting up to 2 million tokens, cramming an entire conversation history into every API call gets expensive. In real-world applications, tokens used for retrieval often account for 30% to 60% of the total LLM expense [11]. Additionally, as context length increases, accuracy declines – important details buried in long inputs are often overlooked, a phenomenon researchers call "lost in the middle" [4][7].
"A 1M-token context window is not a memory system." – Tian Pan, Engineer-Founder [7]
Once conversations exceed 8,000 tokens, aggressive summarization becomes necessary to maintain performance [11]. When immediate context becomes too expensive, external vector memory offers a scalable alternative.
External Vector Memory: Efficient, Scalable Retrieval
External vector memory relies on embedding models to convert text into high-dimensional vectors, storing them in databases like Pinecone or Weaviate. When the agent needs information, it embeds the query and retrieves semantically similar documents. This approach scales efficiently without the high token costs of in-context memory.
However, challenges like training-serving skew – where short queries and long documents are embedded into different regions of vector space – can lead to retrieval errors [9][5]. To address this, hybrid retrieval strategies can be employed. For instance, in 2025, Activeloop used "Deep Memory" technology for a patent system managing 80 million records. By combining vector embeddings with structured metadata (e.g., filing dates, jurisdictions, and types), they improved retrieval accuracy by 5% to 10% compared to pure semantic search [1][8]. While vector memory handles large-scale information retrieval, episodic memory focuses on capturing specific user interactions.
Episodic Memory: A Timeline of Interactions
Episodic memory functions as the agent’s personal history, recording specific interactions, task outcomes, and user corrections. It answers questions like "What did we talk about last week?" or "How was this issue solved before?"
This memory type is typically implemented using a vector store of conversation summaries or task logs, indexed by semantic similarity and temporal metadata [4][7]. Dual indexing – combining vector similarity with time-decay scoring – ensures recent interactions take priority unless older information is deemed critical [7][11]. Early design decisions here directly impact scalability.
To optimize storage, salience scoring can be used to save only key interactions, such as user corrections, task completions, or preference updates [3]. Agents with well-managed episodic memory have shown up to 3.8x higher user satisfaction in repeat interactions [11]. However, careful curation is critical to avoid degrading retrieval quality over time. While episodic memory tracks specific events, semantic memory transforms these into reusable knowledge.
Semantic Memory: Organizing Knowledge
Semantic memory stores structured, factual information that isn’t tied to specific experiences – like user preferences, domain-specific documentation, or entity relationships. For example, it might consolidate facts like "John is our VP of Sales and prefers email over Slack."
This memory type often uses knowledge graphs or retrieval-augmented generation (RAG) systems to maintain consistency across sessions [4][6][11]. A key advantage is its ability to resolve contradictions. For instance, if the agent learns "Enterprise plan costs $500" in one session and "$450 with annual billing" in another, a robust semantic system consolidates these into a single, accurate fact.
Production systems using temporal knowledge graphs, such as Zep‘s Graphiti, have shown an 18.5% improvement in accuracy and a 90% reduction in latency for complex reasoning tasks [1]. However, implementing such systems requires upfront investment in entity extraction, relationship mapping, and conflict resolution logic – challenges that simpler vector-based approaches may not address as effectively.
Production Trade-offs by Memory Type
Each memory type has unique production characteristics that influence performance, cost, and scalability. Let’s break down how these memory types impact real-world production scenarios.
In-Context Memory provides almost instant access since the data is embedded directly in the prompt. However, the downside is that as the context window grows, inference time increases dramatically. For example, a 128K context window requires roughly 128K-squared operations during inference, leading to slower performance and higher costs [12].
External Vector Memory adds a small retrieval delay – typically ranging from 10ms to 80ms. Local solutions like ChromaDB average around 15ms, while cloud-based services like Pinecone can take closer to 80ms [9]. This memory type scales well to millions of entries, with costs shifting from token usage during inference to storage and embedding computation. This shift can lower expenses by up to 60% [14], making it a practical choice for long-term scalability.
Episodic and Semantic Memory share similar latency overheads in production. Episodic memory stores chronological logs that can be easily pruned or summarized, while semantic memory – often implemented as a knowledge graph – requires more complex operations like entity extraction and relationship mapping. This makes semantic memory harder to adjust once implemented [6].
Strategic decisions in memory architecture can significantly improve performance. For instance, optimizing memory design has been shown to reduce p95 latency by 91% (from 17.12 seconds to 1.44 seconds) and cut token usage by about 90% (from 26,031 to 1,764 tokens per conversation). However, these improvements may come with a slight drop in initial accuracy, as seen in earlier challenges with context bloat, where accuracy fell from 72.9% to 66.9% [13].
Memory Design Trade-offs Table
Below is a summary of the production trade-offs for each memory type:
| Memory Type | Latency | Cost at Scale | Scalability Ceiling | Reversal Difficulty | Best Fit for Long-Running Agents |
|---|---|---|---|---|---|
| In-Context | 0ms access; high inference latency due to quadratic scaling | High (quadratic cost) | ~200K–1M tokens | Low (ephemeral) | Poor – context bloat can kill performance |
| External Vector | 10–80ms | Low (storage + embedding compute) | Millions of entries | Moderate | Optimal for scalable, cross-session data retrieval |
| Episodic | 10–80ms | Low (~$0.001–$0.003 per episode) | Unlimited records | Moderate | Excellent – tracks interaction history |
| Semantic | 50–200ms (with graph) | Moderate | Unlimited | High (complex extraction) | Excellent – maintains consistent facts |
"Bigger windows are slower windows. If you’re building interactive agents, this matters." – Bitloops [12]
Designing Tiered Memory Architectures
A single-layer memory design can quickly hit its limits when scaling, but a tiered architecture strikes a balance between speed, cost, and capacity. By 2026, most production agents have moved beyond relying on a single memory type. Instead, they combine multiple layers to handle data efficiently across different time frames and retrieval requirements. This approach ensures your agent can manage information effectively while scaling to meet growing demands.
Core, Recall, and Archival Memory Layers
A tiered memory system typically includes four distinct layers:
- Tier 0 (Working Memory): This is the LLM’s context window. It’s extremely fast but comes with high costs and strict limitations due to token budgets and quadratic compute requirements [5].
- Tier 1 (Session State): Stores recent tool outputs and execution checkpoints in low-latency storage solutions like Redis [5].
- Tier 2 (Episodic/Archival Memory): Keeps long-term interaction histories, indexed by both time and semantic similarity [5].
- Tier 3 (Semantic/Structured Memory): Holds canonical facts, user profiles, and domain-specific knowledge in relational or graph databases [5]. Some systems also include a Tier 4 for high-entropy data like PDFs or large logs, stored as pointers to maintain context window efficiency.
Each layer is designed with specific trade-offs in mind. For example, working memory operates with near-zero latency, while accessing a semantic graph might take 50–200ms. These trade-offs reflect the balance between processing speed and deeper reasoning capabilities [4]. Athenic demonstrated the power of this approach in August 2025, when it implemented a tiered memory system for a customer success agent. The result? A 23% reduction in average call durations and an 8% increase in renewal rates over six months, with only an 85ms increase in latency [10].
Active Self-Management for Agents
Static data retrieval alone isn’t enough for modern agents. They need to actively manage how information moves between memory tiers. This is where a memory controller comes in, using explicit operations like ADD (to store new data), UPDATE (to revise existing information), DELETE (to remove outdated content), and NOOP (to ignore transient data) to maintain a clean and functional memory state [5].
Some systems go even further with paging mechanisms, such as those in MemGPT, which decide what to move to core memory based on task relevance and token budgets [1]. Reinforcement learning routers add another layer of optimization, promoting memory based on task performance. For instance, in early 2026, Fountain City deployed a five-layer memory system with a self-check gate during data extraction. This setup, using the GLM-5-Turbo model, increased the number of useful items extracted during a single reflection session from 1 to 8 [15]. These proactive strategies highlight how early design decisions can shape an agent’s long-term scalability and performance.
"The model’s attention is a bottleneck, not the storage layer. Packaging and presentation often matter more than ranking." – Mjgmario, Memory Engineering for AI Agents [5]
Avoiding Early Flat Vector Commitments
Relying solely on vector storage early in development can be a mistake. While vector databases are excellent for fuzzy similarity searches – helping to "find things like this" – they fall short when it comes to complex reasoning, time-sensitive constraints, and accurate entity matching [6]. For example, without structured entity tracking, a customer who mentioned their spouse’s name three months ago might not be linked to more recent references like "my wife."
The leading design pattern in 2026 is the "Tri-Store" model. This combines vector memory for fuzzy recall, episodic buffers for continuity, and knowledge graphs for precise, entity-focused reasoning [6]. Adopting this model early allows for greater flexibility and complements the tiered architecture by addressing the limitations of any single storage format. A great example of this is Zep’s Graphiti architecture, which uses temporal knowledge graphs. This approach improved accuracy by up to 18.5% and reduced response latency for complex temporal reasoning by 90% compared to baseline systems [1]. The takeaway? Avoid locking into one storage method. Instead, build a system that can integrate knowledge graphs when temporal awareness and entity relationships become critical.
Week-One Decisions That Are Hard to Reverse
The decisions you make about memory architecture in the first week of development can lock you into a path that’s nearly impossible to change later. For example, between January and April 2026, the Katelyn Skills OS platform ran over 300 sessions using three untyped, independent memory stores. This setup led to a 1-in-8 failure rate in maintaining coherence across sessions. However, in March 2026, Graph Digital founder Stefan Finch restructured the system into four typed layers with structured state management. The result? Over 150 subsequent runs with zero cross-session coherence failures. Debugging also became much faster, shifting from multi-session investigations to single-session resolutions [17]. This case highlights how early architecture choices significantly affect both system performance and long-term maintenance. It also serves as a warning against relying on a monolithic approach, emphasizing the importance of thoughtful memory structuring.
Monolithic Context vs. Tiered Memory
Dumping all historical data into a single context window might work for the first 30 to 150 conversations, achieving an accuracy range of 70–82%. But as complexity increases, performance plummets to 30–45% [7]. The problem lies in the exponential growth of compute costs. Doubling the context window results in roughly four times the attention compute cost, making monolithic models unsustainable at scale [1][8]. For instance, a single 128K-token request could require hundreds of gigabytes of key-value cache [1][8]. Once workflows are built around a monolithic model, transitioning to a tiered memory structure becomes a massive undertaking. It requires reworking the decision-making loop, state management, and data persistence – a shift that turns what could have been a simple week-one decision into a months-long engineering challenge.
Passive vs. Active Retrieval Strategies
Passive retrieval treats memory as an add-on, embedding all data and retrieving it based on similarity. This approach is straightforward but limited. Active retrieval, on the other hand, is far more dynamic. Here, the agent actively decides when to retrieve information, what to query, and whether the retrieved data is sufficient [1][16]. Implementing active retrieval requires managing state across multiple tiers and embedding retrieval logic directly into the agent’s policy or tool-use framework. If you start with passive retrieval and later decide to switch to active retrieval, you’ll need to redesign the core reasoning loop – a costly and complex process.
"Memory is not a feature. It is the architecture." – Frank, The Agentic Blog [16]
This quote underscores how your choice of retrieval strategy shapes the system’s adaptability for future changes.
Vector-Only vs. Knowledge Graph Augmentation
Relying solely on vector-based memory can create significant limitations. While vector stores are excellent for fuzzy recall, they struggle with tasks like following multi-step relationships (e.g., "Who referred the client who churned last month?") or maintaining precise temporal sequences [6]. Many so-called hallucinations are actually retrieval errors caused by the flat structure of vector stores [6]. If you store thousands of episodes in a vector format, migrating to a knowledge graph later becomes a major research and development effort [18].
"The shared context blob doesn’t degrade at a steady rate. Each agent that joins the system multiplies the noise – by the time you have four or five agents reading the same store, errors compound on top of errors." – Stefan Finch [17]
To avoid these pitfalls, consider adopting a Tri-Store model early. This approach combines vector memory for fuzzy recall, buffers for episodic continuity, and knowledge graphs for precise entity reasoning. By doing so, you reduce the risk of being locked into a single, inflexible memory format [6].
Conclusion: Building for Scale from Day 1
The memory architecture decisions you make in the first week can determine whether your AI agent thrives or hits a wall. When built on a solid framework, memory-enabled assistants can cut task completion times by 34% compared to stateless systems [10]. The line between a flashy demo and a production system delivering real ROI often lies in the groundwork laid before the first line of code is written.
Understanding the four memory types – in-context, external vector, episodic, and semantic – is key to making informed trade-offs. Each type has its own scalability challenges: in-context memory becomes expensive at scale, vector stores lose effectiveness without hybrid retrieval, and episodic and semantic memory need to work together. Hybrid retrieval systems, when designed early, can outperform pure vector search by 15–30% on recall metrics [2].
To avoid scaling bottlenecks, layered solutions are essential. Tiered architectures that separate working memory, episodic buffers, and semantic stores are effective at sidestepping the limitations of monolithic designs. The Tri-Store pattern – combining vector memory for fuzzy recall, buffers for maintaining continuity, and graphs for entity reasoning – has emerged as the go-to production strategy by 2026. This approach balances speed, capacity, and cost while keeping your retrieval strategy flexible [6]. Early implementation of quotas, salience scoring, and latency budgets ensures that your system remains responsive as memory demands grow.
The hardest choices to reverse – like opting for a monolithic context over a tiered memory system, passive versus active retrieval, or vector-only methods versus knowledge graph augmentation – are the ones you face from the very beginning. These decisions can make or break your system’s scalability, and rearchitecting memory post-launch can lead to months of costly engineering work. Build with scale in mind from the start, and you’ll turn potential limitations into long-term advantages.
FAQs
What’s the simplest tiered memory stack I can ship in week one?
The most basic type of tiered memory setup is in-context memory, which keeps the conversation history right within the model’s context window. Essentially, user messages and assistant responses are added to a running list. As the token limit gets closer, older messages can be either truncated or summarized. This approach is quick, temporary, and works best for short-term tasks or one-off interactions. Plus, it’s easy to set up and can often be implemented in just a week.
When should I stop stuffing history into the context window and switch to retrieval?
When the context window starts to feel like a bottleneck – whether because of high costs, latency issues, or token limits – it’s time to consider retrieval-augmented memory. Overloading the context window can lead to slower performance, higher expenses, and even less accurate results.
A smarter approach? Use tools like external vector stores, episodic summaries, or semantic memory. These methods let you retrieve relevant past data efficiently, ensuring your long-running agents stay scalable while keeping their context sharp.
How do I keep vector-based retrieval from getting worse as my agent scales?
To keep vector retrieval efficient as your agent scales, consider using a hybrid retrieval architecture. This approach blends semantic vector search with keyword or graph-based methods, which helps boost recall. Additionally, implementing layered pipelines can refine results by re-ranking them for better accuracy.
Regularly consolidating and pruning your data is key to preventing unnecessary bloat. As your data grows, distributed vector storage with efficient indexing becomes essential to maintain both low latency and high accuracy. These strategies work together to ensure your system performs reliably, even at scale.
Related Blog Posts
Huzefa Motiwala
Huzefa Motiwala is a co-founder of AlterSquare, an application-layer partner that helps SaaS and tech-led companies stabilise, modernise, and extend complex systems without breaking what already works. He comes at software from design and frontend, with a focus on data-heavy interfaces and on getting real teams to actually adopt what gets built — not just ship it. He writes about working in fragile, high-stakes codebases: incremental change over risky rewrites, UX and technical debt, and embedding AI into real workflows.







Leave a Reply